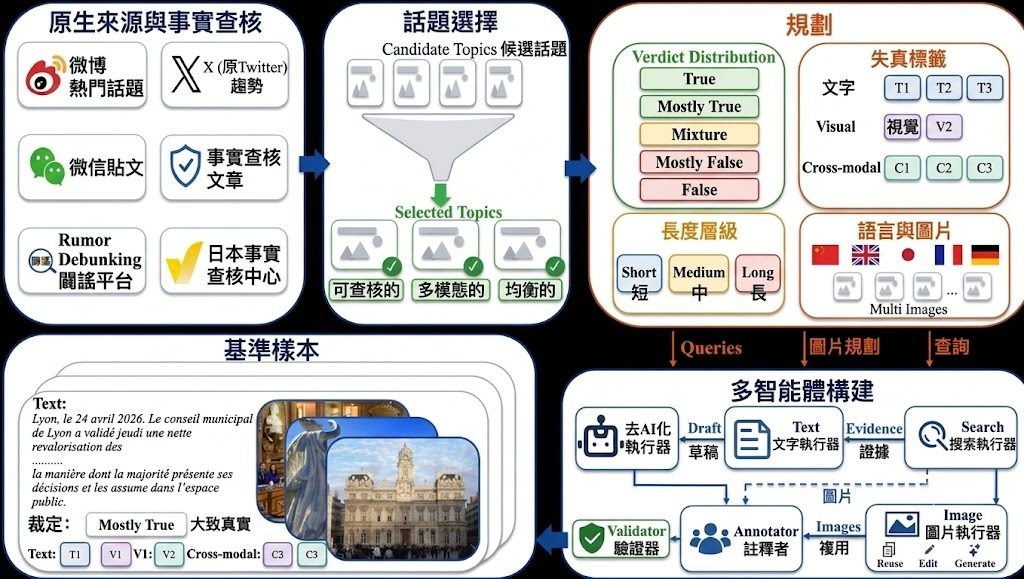
開發團隊來自上海交通大學、上海人工智慧實驗室、清華大學、中南大學,以及中國電子科技集團第十五研究所,核心作者把 ReMMDBench 同 ReMMD-Agent 一起公開,方向很明確:用較接近真實網絡帖文的方式,檢查圖文混合內容中的 misinformation。這個 GitHub 項目屬於研究原型加評測代碼集合,主要用來重現三個 multimodal misinformation detection agent 系統在 ReMMDBench 上的結果,並比較它們怎樣做判斷。
現有做法常把多模態假資訊檢測收窄成單圖、二分類,或者一次過把整段文字與圖片丟給模型判斷;作者認為這種 fixed-pass 判斷方式難以處理長敘事、多張圖片、跨語言與部分真實內容。這個項目因此提出一套以 ReMMDBench 為核心的 agentic 驗證路線:Baseline 1 是 3-stage MMD-Agent,Baseline 2 是 MCTS-based 5-verdict + 8-taxonomy agent,而主系統 ReMMD-Agent 則用 atomic decomposition、RAG(Retrieval-Augmented Generation)與 multi-expert judge,把結論建立在可追蹤的證據狀態上。
跟同類方法相比,ReMMD-Agent 的取向不是只追求一次答中,而是先把帖文拆成 atomic claims、image observations、text-image bindings,再檢索 multimodal evidence,之後重用 persistent memory,減少重複工具呼叫。這種設計的取捨很清楚:流程更長、配置更多,但換來較好的可解釋性,也更適合處理 five-way L1 veracity labels、8 個 L2 distortion labels,以及 multilingual multi-image 場景。
安裝與測試思路也相當具體。三個子項目各自有 requirements.txt、設定檔與啟動腳本;要先把資料根目錄指向 ReMMDBench,再在 .yaml 或 .env 內填入模型端點與金鑰佔位內容,之後可先用 mmd-agent/test_qwen.py 這類健康檢查確認後端可回應,再跑各自的 evaluation scripts。倉庫已附上 Qwen-family 後端的保存結果與 artifacts,包含 Qwen 4B、9B、27B,亦明確標示 temperature = 0.0、LLM caching 與預建 RAG index,方便重現 headline numbers,而不必由零開始建立整套流程。
- 主系統:ReMMD-Agent,核心結構是 atomic decomposition + RAG + multi-expert judge
- 對照系統:3-stage MMD-Agent 與 MCTS-based t2-agent,方便看不同 agent 設計的取捨
- 資料與標註:ReMMDBench 有 500 samples、2,756 images、5-way L1 與 8 類 L2 標籤
- 相關模型:Qwen-family 4B / 9B / 27B;首頁亦提到 GPT-5.2 曾用於 leaderboard
- 較適合的情境:研究團隊、事實查核流程設計者、多語內容審核與 agent benchmark 比較
性能方面,倉庫重點是重現論文中三套系統在 500-sample ReMMDBench 的結果,而不是提供一個即裝即用的線上服務。它較適合拿來做 benchmark 驗證、分析不同 agent pipeline 的表現,或者研究 evidence reuse 對多模態判斷有幾大幫助;要直接放進產品,仍要自行補回資料接入、服務封裝與更穩定的推理基建。