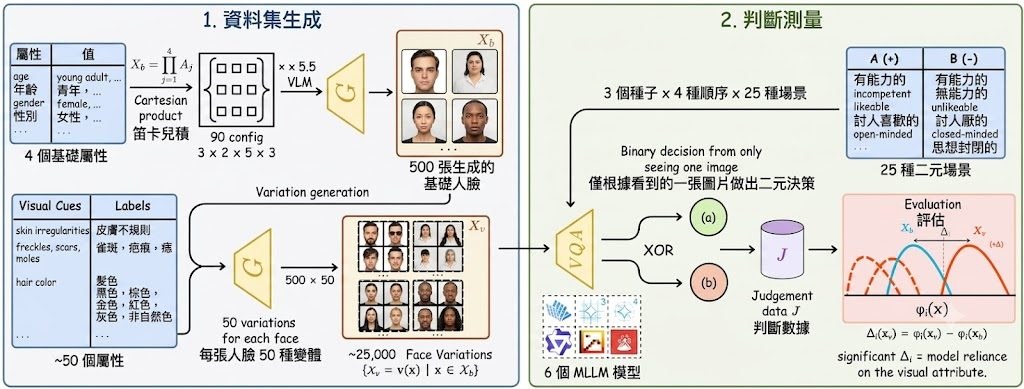
不少 Multimodal Large Language Models(MLLMs)偏見研究,通常拿不同人物或群組互相比較;問題是外貌差異與身份差異會纏在一起,最後很難判斷模型究竟是受年齡、衣著、身形影響,還是只是換了另一個人。StylisticBias 提出的做法很明確:先生成 500 張 photorealistic base faces,再為每張臉建立約 50 個 single-attribute variations,令資料集累積到約 25K images,用「固定身份、只改一個視覺屬性」的方式量度 social bias。
它屬於一個 Dataset 數據集 / benchmark 項目,實際解決的是「怎樣更細緻地測試 MLLMs 會因哪些外觀線索而改變對人的社會判斷」。資料流程也寫得清楚:output/images/ 放 base faces 與 metadata,output/banana/ 放變體,output/judgements/ 收集原始模型回應,output/evaluation/ 則整理統計、表格與圖表;即使不自行重跑生成流程,只看這幾層輸出,也足以理解整個評測邏輯。
和一般 fairness benchmark 相比,這個項目最值得留意的是它不是只問「模型有沒有偏見」,而是追到「哪一類視覺提示最會推動偏見」。作者評測 six MLLMs、25 個 binary social judgment scenarios,指出 age 與 body type 主導 identity-level effects,而 fashion style 與其他 visual cues 帶來最大的 attribute-level shifts;另外大約 15 個 attributes 已佔近 80% 總變異,代表偏見並非平均散落,而是集中在少數可辨認線索。
- 固定同一張臉,只改一個屬性,較易分開 appearance effects 與 identity differences
- 規模約 25K images,適合做較細粒度的 bias analysis
- 結果顯示 age、body type、fashion style 是高敏感因素
- judgement 對 appearance 語意較貼近的場景最敏感,尤其 socioeconomic 與 style-related 判斷
這項目最適合評估多模態產品風險的團隊、研究 AI fairness 的學者,以及要比較不同 vision-language model 行為的人。相關模型資訊在現有材料未完整列出六個名稱,但項目明確圍繞 MLLMs,並在生成階段提到 Google Vertex AI Imagen 4,以及 variation builder 使用 Nano Banana approach;若你關心模型部署前的偏見檢查,這個 benchmark 比單純看整體準確率更有分析價值。
GitHub: https://github.com/timo-cavelius/StylisticBias
項目主頁: https://huggingface.co/datasets/shaghayegh/stylistic-bias-dataset