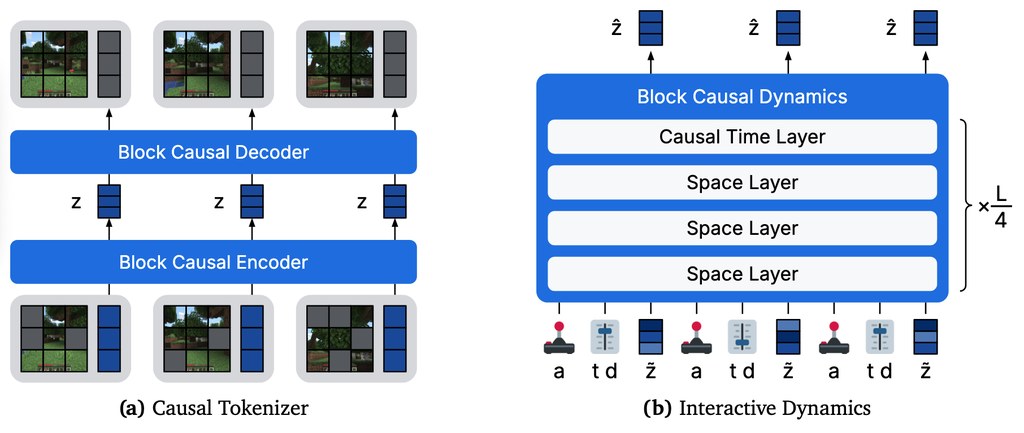
ConvFill 是一個用來建立語音代理的開源系統與研究原型。能夠實現即時回應和準確回答——這兩個目標通常難以兼顧。它將本地運行的小型快速語言模型與在後台進行繁重推理的大型雲端模型相結合,使代理能夠立即開始對話,並在資訊可用時自動填充合理的答案。此程式碼庫包含完整的系統、一個即時語音演示、七個即用型模型以及訓練您自己的模型所需的一切資源。
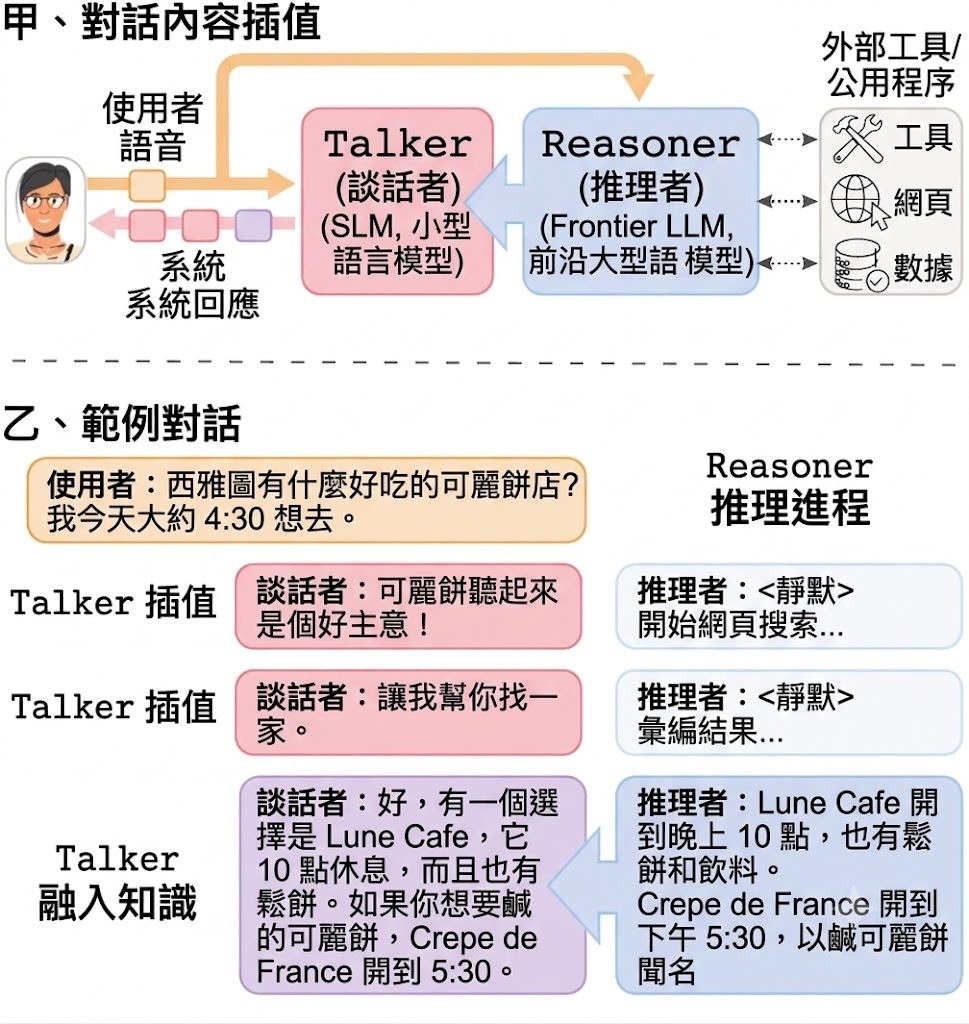
現有做法通常要麼直接等大型模型完整生成,回應較慢;要麼改用較小模型追求低延遲,但複雜查詢、文件搜尋同工具調用能力會明顯下降。ConvFill 提出 conversational infill 這個新任務,將 Talker 與 Reasoner 分工:Talker 先即時說話,Reasoner 在背景處理慢工序,再把精簡知識流式交回 Talker 融入回答。
ConvFill 不是單純做語音介面,而是重新安排推理時序。Talker 可用 135M 到 1.7B 參數的小模型,在手提電腦或手機本地運行;Reasoner 則可接 Claude、GPT 或 Gemini。儲存庫已提供 live voice demo、七個現成模型,以及訓練自家 Talker 所需內容,理解上可視為「本地即時對話層 + 雲端能力層」的組合。
- 內置七個已微調 Talker,涵蓋 Qwen、Llama、Gemma、SmolLM 家族
- 配套 ConvFill dataset,含 290,571 個經驗證訓練樣本,覆蓋六個領域
- Reasoner 可替換為 Claude、OpenAI 或 Gemini,毋須為更換 Reasoner 重新訓練
- 論文指出系統可維持 millisecond-level time-to-first-response,準確度與對應 frontier Reasoner 的差距縮至 6.3% 內
受益最明顯的,會是想做客服、助理、查詢式語音介面或需要邊說邊找資料的團隊。它未必適合完全離線、又要求深度推理的場景,因為關鍵能力仍依賴雲端 Reasoner;但對希望保留本地回應速度,同時接入大模型能力的項目,這套設計比單模型方案更有工程上的彈性。