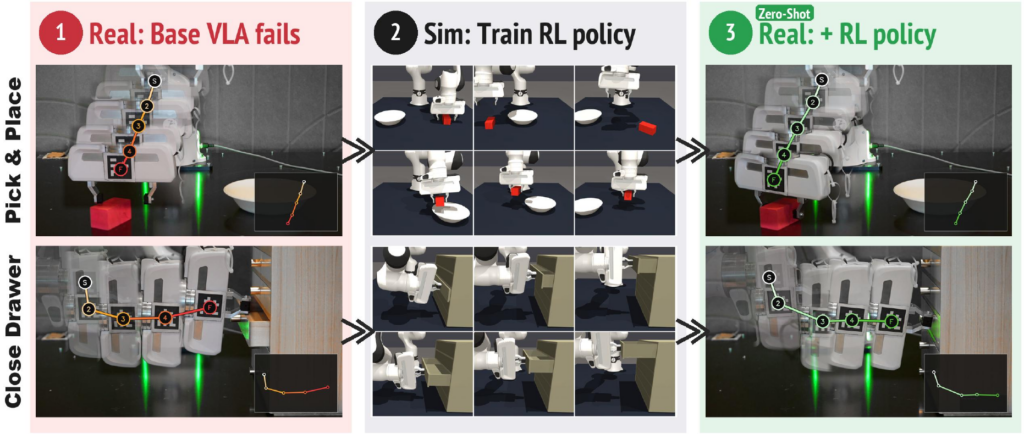
NeuraDock/eeg-workstation-agent 是一個本地優先的 Python 工具項目,也可視為面向應用整合的 EEG agent。它主要將 NeuraDock EEG Workstation 的 7 通道腦電訊號,轉成經過質量檢查的 visual cognitive-load 狀態,讓介面、XR、車載 HMI 或互動系統可以即時讀取,而不必直接處理原始 EEG。
現有不少 EEG 流程會把重心放在原始波形顯示、離線分析,或讓開發者自行拼接 preprocessing、quality control 與特徵提取;作者在技術文件中明確反對讓通用 LLM 直接對感測結果作自由解讀的做法。這個項目的取向,是把 deterministic local EEG engine 與 hardware-aware language layer 分開:前者負責解析、前處理、spectral workflows 與 machine-readable artifacts,後者只接收 allowlisted summary 與 versioned context pack,避免模型對 7-channel EEG 說出超出量測邊界的結論。
部署路線算清晰。儲存庫列出 Python 版本範圍、支援 Windows、macOS、Linux,亦提供無硬件 synthetic replay,所以就算未買 NeuraDock EEG Workstation,也可以先啟動本地 dashboard 與 API,檢查 GET /api/status 會輸出哪些欄位;真正連接裝置時,Agent 會經 TCP 收流、做 online preprocessing,再輸出如 visual_load_index、alpha_peak_hz、alpha_suppression_from_baseline 及 quality.status 等狀態。示例資料要到另一個資料儲存庫下載,這裡沒有直接附上人類 EEG 數據,反映作者對資料安全與分發邊界相當保守。
和同類做法相比,它的差異不在「能否分析 EEG」,而在於它刻意收窄可宣稱的範圍。這套工具聚焦 posterior Alpha dynamics、within-subject Rest/Task visual cognitive-load comparison,以及 quality-gated adaptation,並清楚說明它不是 medical device,亦不能直接診斷 attention、fatigue、impairment 或跨個體比較表現。這種取捨令它的野心比一些泛用腦機介面平台細,但換來較可控的輸出與較低的誤讀風險。
- 定位明確:屬於本地執行的 EEG 分析工具項目,重點是把 7 通道訊號轉成應用可讀狀態。
- 測試門檻較低:有 synthetic replay,未接硬件都可以先驗證 dashboard、API 與流程。
- 邊界控制做得細:LLM 不接觸 raw EEG 與 dense time-series arrays,只接收精簡指標與受控上下文。
- 適合即時互動場景:視覺搜尋、adaptive vehicle HMI、cognitive load game 都是直接示範。
- 資料解讀有限制:結果偏向個體內比較,不適合把不同人的 workload 分數直接放在同一把尺上。
性能描述方面,技術報告提供了幾個辨識度很高的訊號。其一,12 份錄音在十次 numerical repetitions 下得到相同 structured results,完整 Rest/Task 執行在三次重跑下亦產生相同 result、report 與 figure hashes,說明 deterministic pipeline 不是口號。其二,作者做了 request-capture 與 failure-injection experiments,檢查資料邊界與本地 artifacts 在 HTTP、格式錯誤及連線失敗下是否仍能保留。其三,boundary-awareness benchmark 涵蓋 ordinary 與 adversarial questions,並結合 qwen3.7-max 和 kimi-k2.6 生成輸出;這部分重點不是比較哪個模型最聰明,而是檢查語言層有沒有超越硬件與工作流容許的解釋範圍。
相關模型與組件方面,README 沒有把核心 EEG 推理包裝成 foundation model,而是以 reviewed workflows 為中心;可見的外部模型主要是 optional LLM mode 會用到的 LLM,例如 qwen3.7-max、kimi-k2.6。適合受益的人,包括做 HCI、XR、遊戲互動、復健訓練、工業監測與研究原型的團隊;他們想要的通常不是一套醫療級診斷系統,而是一個可以穩定輸出、容易接入前端或控制邏輯、又盡量把資料留在本機的腦訊號工具鏈。
項目主頁 · GitHub · Paper