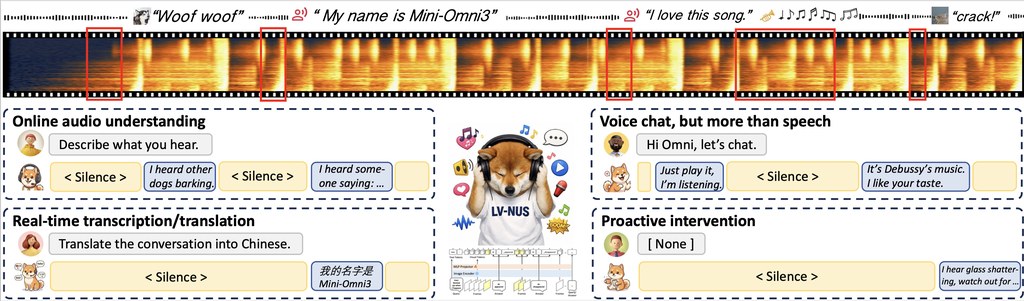
很多影片生成方法處理編輯任務時,會把過往畫面當成單一記憶來源;一旦做了 style、season、weather 或 time 這類修改,舊記憶就可能變成過時參考,之後生成的鏡頭容易出現人物變樣、場景走位錯亂,或者視角切換後對不上。PermaVid 提出的方向,是把「外觀語意」同「幾何結構」分開保存,避免一次編輯令全部上下文一齊失效。
這是一個影片生成框架,核心工作是讓 edited video 在跨時間、跨視角、跨多次修改之下,仍保持內容連貫。它使用 disentangled context memory:RGB context memory 負責記錄 semantic appearance,depth context memory 則保留 geometry-only structure,再配合 edit-aware memory update and retrieval,把新修改過的資訊逐步寫回記憶。
和一般只靠單一記憶庫或單一路徑條件控制的方法相比,PermaVid 的取捨很清楚:系統更複雜,也要同時處理 RGB 與 depth 兩種脈絡,但換來的是編輯之後的長期一致性。從儲存庫資訊看,項目亦提供 dataset、paper 及 demo,並依賴 Wan2.1-VACE-14B、Qwen-Image-Edit、Qwen3-VL-8B-Instruct 等模型,顯示它不是輕量玩具,而是偏研究型、多模組組合的完整流程。
- 支援相機移動控制,例如 direction-frames-speed 這類格式
- 編輯類型涵蓋 style、season、weather、time 等全局變化
- 重點不只是生成單段片,而是修改之後仍維持後續片段一致
- 需要較完整環境配置,包含 PyTorch、CUDA 與額外訓練/推理依賴
如果你是做 instruction-based video editing、reference video generation,或者想研究 Computer Vision 同多模態記憶如何影響長片段一致性,這個項目很有參考價值。現有資料提到它在長期 semantic 與 structural consistency 上明顯優於 state-of-the-art methods,但公開資訊未列出完整量化分數;較穩妥的理解,是它的亮點在方法設計與 benchmark 表現方向,而不是即裝即用的消費級工具。
GitHub: https://github.com/YS-IMTech/PermaVid