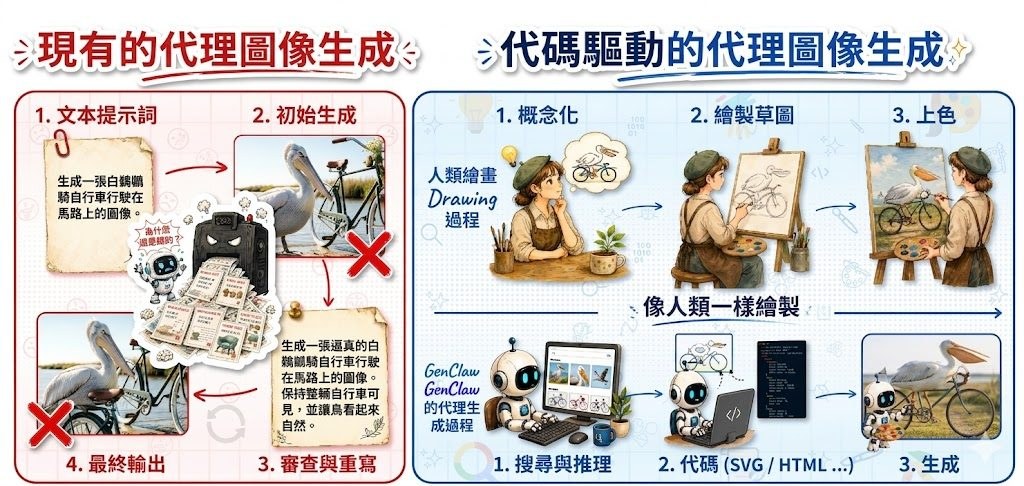
GenClaw 是一個研究中的項目,核心不是不停改 prompt,而是把程式碼變成可控制的視覺草稿,再交給圖像模型完成渲染。對一般讀者來說,可以把它理解成先畫草圖、定位置、排文字,之後才交由 AI 上色和補質感。
這個項目想處理的痛點很明確:很多 image generation 流程仍然像黑盒,生成失敗時只能反覆重寫提示詞碰運氣。GenClaw 將流程拆成 concept、sketch、render 幾步,令畫面中的物件數量、空間配置,甚至文字排版,都有機會透過可執行程式直接調整。
這做法結合搜尋、推理與程式繪圖,使用 SVG、HTML/CSS、Python,亦提到 Three.js 這類輕量 3D 方式來建立中間畫布;最後再調用 image generation model 補上材質、光影與真實感。這種設計比單次生成更容易檢查、修改,亦較貼近人類由草稿到完稿的創作步驟。
- 把程式碼當成視覺畫筆,而非只靠文字提示
- 適合複雜場景、海報文字、空間佈局等要求較高的畫面
- 中間結果可檢查與回退,降低黑盒生成的不確定性
- 論文提到可配合 GPT-Image、Qwen-Image、Nano-Banana 一類模型理解其定位
現階段要留意的是,儲存庫已公開 technical report,但 code 和 demo 仍在準備中,所以目前較適合先讀論文了解方法,再觀察後續釋出。從論文描述看,它較適合做視覺生成研究、代理系統開發,或者需要高控制度圖像流程的團隊;至於效能評估,公開頁面以方法與示例為主,較完整的量化表現仍需以論文內容和日後程式發布為準。