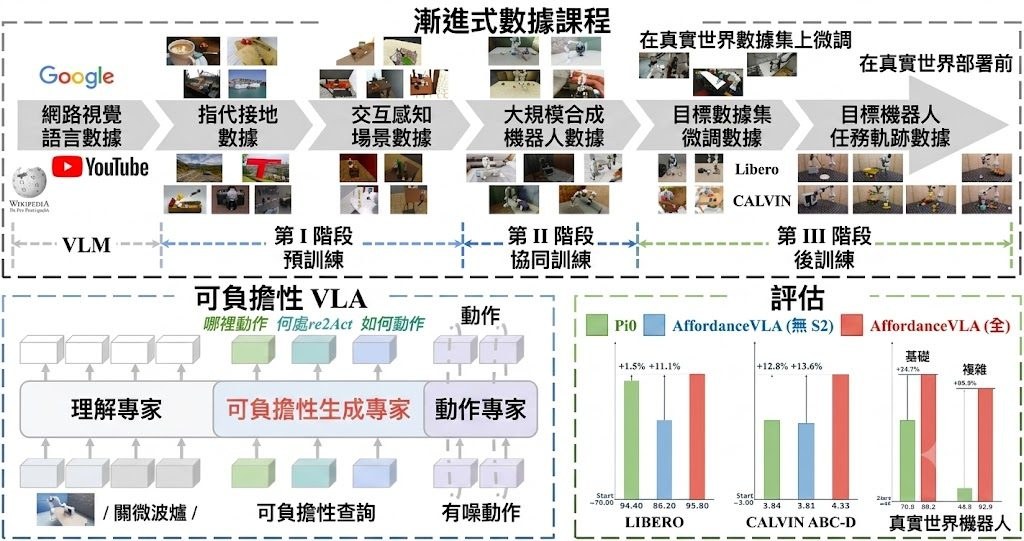
機械臂聽到「把杯子拿起來」這類指令時,傳統的視覺語言動作模型(Vision-Language-Action Model, VLA)往往要直接把影像和文字翻譯成關節角度,中間欠缺一個「思考」步驟。AffordanceVLA 嘗試在這個鴻溝上架一道橋:先讓模型預測結構化的可供性(affordance),再據此生成動作。
整個框架由三個專家模型組成,按單向的 UAA 注意力串接。Understanding Expert(M_und)以 PaliGemma(SigLIP + Gemma)為骨幹,把畫面、指令與機械臂自身狀態融合成統一的語意表示。Affordance Generation Expert(M_gen)以 Gemma 搭配可學習查詢,把上述表示解碼為三種可供性標記:Which2Act 判斷要操作的物件、Where2Act 標出二維互動熱區、How2Act 則推估三維幾何資訊。最後 Action Expert(M_act)以 flow matching 方式輸出整段動作序列(action chunk)。這個設計呼應了論文「Affordances serve as a perfect bridge」的核心想法。
由於現成機器人數據集中缺乏密集的可供性標註,作者額外提供了一條自動化標註管線,並以三階段漸進式課程訓練 MoT 架構。訓練時須留意 model.chunk_size 與 data.chunk_size 保持一致,否則動作 attention mask 會錯位;Which2Act 的 Flux loss 預設為 MSE,可在 src/models/which2act_decoder.py 頂端切換。
這個項目適合研究 VLA、機器人操作策略,或對可供性表示有興趣的開發者。需要一支能跑 PaliGemma 與 flow matching 的 GPU 環境,並準備好仿真或實機評測流程。論文中的模擬與真機實驗橫跨多種操作場景,顯示加入可供性中間層能提升泛化與精確度,但具體數字仍以官方報告為準。
重點摘要
- 以 Which2Act、Where2Act、How2Act 三段式可供性作為視覺、語言與動作之間的中間橋樑。
- 採用 MoT 架構,串接 PaliGemma 為基礎的 Understanding、Gemma 為基礎的 Affordance 與 Action Expert。
- 配套自動化可供性標註管線,緩解機器人數據標註不足的問題。
- 訓練採三階段漸進式策略,flow matching 輸出整段動作序列。
- 模型、訓練與標註腳本皆隨開源項目釋出,歡迎社群延伸。