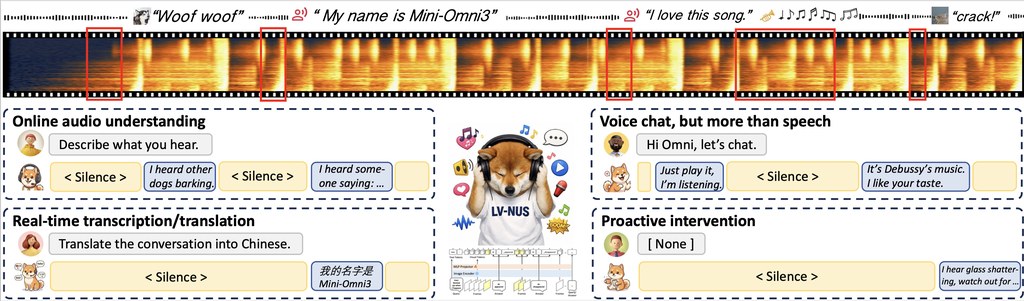
Audio-Interaction 是一款由南洋理工大學(NTU)、新加坡國立大學(NUS)及香港中文大學(CUHK)共同研發的全開源音訊語言模型,屬於新一代的 Audio Interaction Model(音訊互動模型)。它以一個始終運行的感知—決策—回應循環(perceive-decide-respond loop)為核心,能即時聆聽環境聲音與指令,並自行判斷何時應該開口回應。
傳統的大型音訊語言模型大多只支援離線處理,而現有的串流模型一般只能做單一任務,例如即時語音辨識(streaming ASR)或語音聊天。Audio-Interaction 以單一架構同時覆蓋離線與即時任務,把辨識、翻譯、對話等不同功能統一在同一條串流中。這意味著開發者只需要一套模型,就能應付多種音訊互動場景。
這個項目的核心創新在於其訓練流程 SoundFlow。它能把短音訊片段拼接成長互動資料,並以「塊級決策訓練」(chunk-level decision training)配合歷史回顧與語意感知的靜音處理,讓模型學會「該不該說話」。在推論階段,SoundFlow 採用異步 FIFO 推論(asynchronous FIFO inference),使首幀延遲降低約 4.5 倍,帶來更流暢的即時體驗。
使用時,開發者可以直接從官方頁面取得技術報告與程式碼,並透過微信群組加入社群討論。該項目亦提供了即時試聽 Demo,可與 OpenAI 的 gpt-realtime 及字節跳動的 Seeduplex 進行同條件比較,在重複聲響計數、咳嗽辨識及音樂風格判斷等場景中,Audio-Interaction 能逐輪輸出有意義的回應。
Audio-Interaction 重點摘要:
- 統一架構:以單一模型同時支援離線與即時音訊任務,涵蓋辨識、翻譯及對話。
- 感知—決策—回應循環:模型自行判斷回應時機,貼近真實人機互動節奏。
- SoundFlow 訓練流程:結合資料拼接、塊級決策訓練與靜音感知,提升即時判斷能力。
- 低延遲推論:異步 FIFO 推論使首幀延遲降低約 4.5 倍。
- 完全開源:提供技術報告、程式碼及即時試聽 Demo,方便研究與應用。
這個項目特別適合從事語音 AI、對話系統及多模態互動研究的開發者與團隊,能為需要即時音訊理解的產品,例如智能助手、會議記錄、聽障輔助等,提供一個統一且靈活的基礎模型。