這個項目來自跨校團隊,作者包括 Yiming Ren、Yiran Xu、Zicheng Lin 等人,通訊作者是 Yu Qiao 與 Ruihang Chu;所屬機構包括清華大學、上海人工智慧實驗室、香港中文大學及香港城市大學。以研究背景看,團隊明顯集中在大型語言模型訓練、推理強化學習與數學評測。
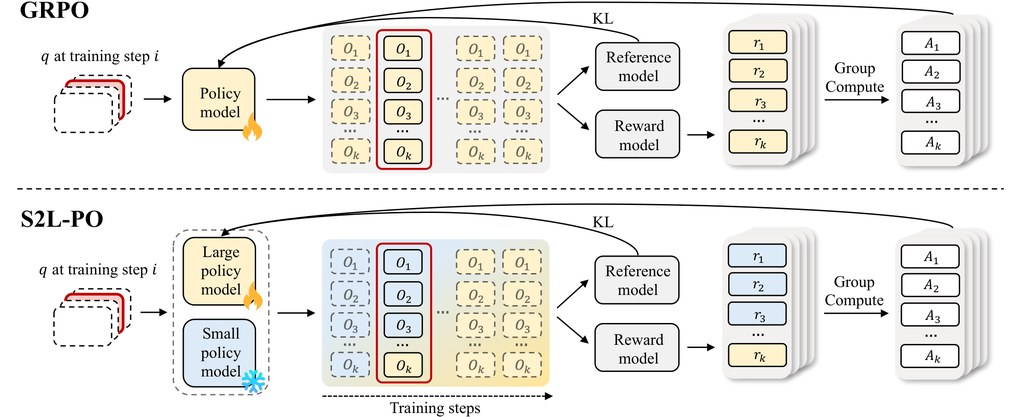
這是一個針對 Group Relative Policy Optimization(GRPO)訓練流程的研究型框架,目的是提升大型語言模型在推理任務上的 rollout diversity。現有做法多數靠提高 temperature,從 token-level randomness 增加變化,但論文指出這種固定範式容易在長推理鏈累積噪音,令軌跡變得不連貫。
S2L-PO(Small-to-Large Policy Optimization)換了一個角度:不用同一個大模型不停抽樣,而是找同家族的較小模型做 explorer,先產生一部分 qualitatively different reasoning trajectories,再讓大模型用混合 rollout 依照標準 GRPO 訓練。之後再用 progressive annealing,逐步由 small-model exploration 過渡到 fully on-policy learning,避免中途被小模型能力上限拖慢。
論文提供的結果頗有說服力。以 Qwen3-8B learner 配 1.7B explorer 為例,AIME24 Pass@1 由 15.0 提升到 23.8,AIME25 Pass@1 由 12.1 提升到 22.5;Qwen3-14B learner 配 4B explorer 亦比基線 GRPO 高。作者同時聲稱 rollout compute 還可降低,這點對訓練成本敏感的團隊尤其有吸引力。
如果你想測試這個項目,較合理的方式不是當作即裝即用工具,而是把它視為一個訓練策略參考:先看論文與公開模型設定,再比較自己手上的 GRPO 流程是否同樣受 rollout 同質化影響。硬件門檻不算低,資料列出 8B 模型約需 20 GB GPU 記憶體、14B 模型約需 32 GB,較適合研究人員、模型訓練工程師,或正在做數學推理微調的團隊。
- 核心判斷:這是模型訓練框架,不是一般聊天應用,重點在改善 GRPO 的探索品質
- 方法差異:由 token-level randomness 轉向 policy-level diversity,減少長鏈推理失真
- 主要創新:用較小同家族模型充當 natural explorers,再以 progressive annealing 收回大模型主導權
- 已列相關模型:Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B
- 適合場景:數學推理、可驗證獎勵訓練、想提升 RLVR 與 GRPO 收斂效率的項目