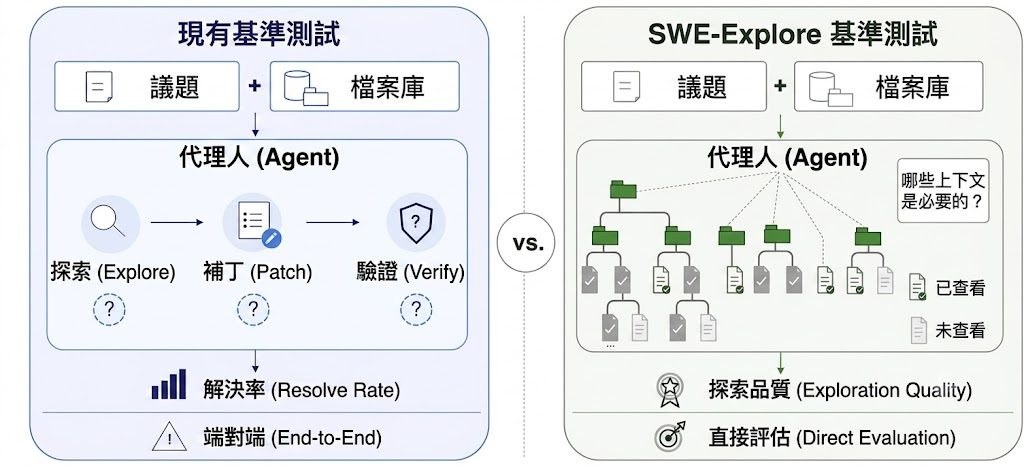
SWE-Explore-Bench 由上海交通大學、香港中文大學等團隊推出,專門考核編碼代理在「真正落筆修改前」探索程式碼庫的表現。現有的 SWE-bench 等基準只給出最終通過與否的二元結果,難以分辨代理是因為找對位置而成功,還是碰巧蒙對。這個項目把探索這一步抽離出來單獨計分,更貼近診斷代理能力的本質。
具體做法是收集同一議題的多條成功修復軌跡,從中抽取代理實際讀取的程式碼行範圍,整合出共識的核心上下文,再保留部分模型獨有的可選上下文。代理需要輸出一份按行範圍排序的程式碼區域清單,評分涵蓋覆蓋率、排序品質、上下文效率,以及下游受限修補驗證四個維度。這種行級監督比傳統的檔案級定位更細緻,能揭示代理的真正瓶頸。
資料集涵蓋 10 種程式語言、203 個開源項目中的 848 個議題,並提供 OpenAI 相容的端點,方便接駁不同 LLM 進行行範圍精修。實測結果顯示,具備代理能力的探索器明顯領先傳統檢索器,現代方法在檔案層級已相當成熟,但行級覆蓋與高效排序仍是區分頂尖方案的分水嶺。
適合關注 SWE-agent、AutoCodeRover、OpenHands 等代理框架的研究者、開發者及基準設計者使用。對想了解自家代理「讀碼環節」強弱的團隊而言,這是一個值得放入評測管線的參考項目。