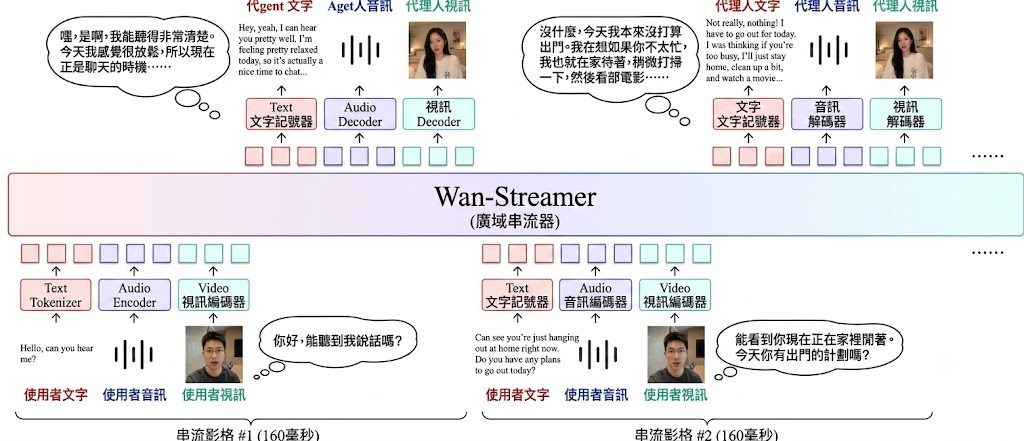
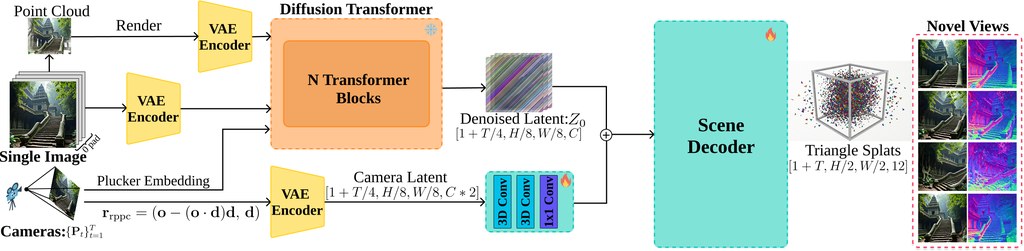
FLAT(Feedforward Latent Triangle Splatting)是一個由 Google Research、牛津大學 Visual Geometry Group 與慕尼黑工業大學共同開發的 3D 場景生成項目,主打從影片擴散模型的潛在表示中,單次前向解碼出幾何準確的三角形面片場景。
開發團隊方面,FLAT 由 Orest Kupyn、Goutam Bhat、Philipp Henzler、Fabian Manhardt、Christian Rupprecht 與 Federico Tombari 等研究員共同發表,核心作者來自 Google Research,並與牛津大學 Visual Geometry Group 及慕尼黑工業大學合作完成。
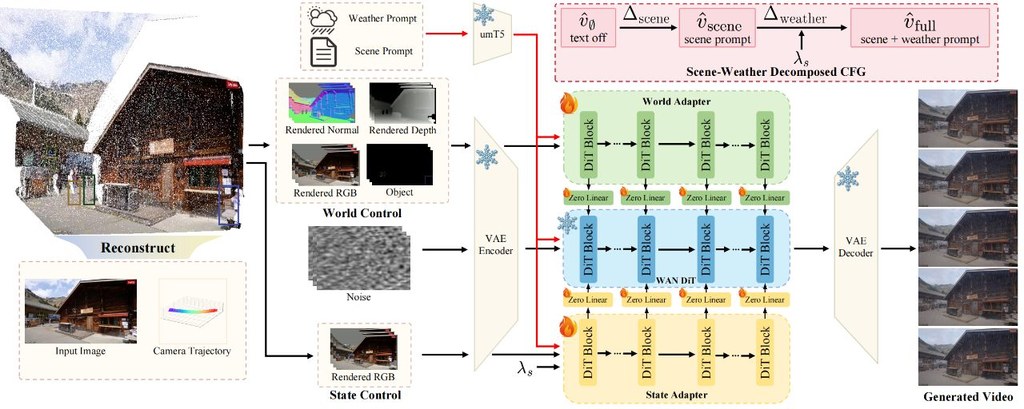
與常見做法相比,FLAT 跳過了「先生成再優化」的兩階段流程,直接從壓縮的影片擴散潛在特徵預測三角形面片,而非 3D 高斯體素。這項差異讓輸出結果在幾何精度上更貼近真實表面,同時保留視覺品質,並能直接用簡單的三角形渲染器顯示。
和同類方法相比,這個項目的取向很鮮明:它不是先做一般影片理解,再另外接 motion head,而是把 language-guided 3D point trajectory forecasting 當成核心任務。代價是輸入要求較多,你要有 query points 同初始 3D 資訊;回報則是輸出更貼近規劃用途,特別適合要預測「物件將會點樣郁」而不是只想分類場景的人。
可預測最長約 2 秒未來軌跡,文件提到 15 fps、F=30 或 F=32 的設定
評測指標列出 ADE、FDE、PWT,焦點放在軌跡準確度而非只看畫面相似度
配套包含 MolmoMotion-1M 訓練資料集與 PointMotionBench 評測基準
作者指出學到的 motion prior 可轉移到 robotics planning 與 motion-guided video generation
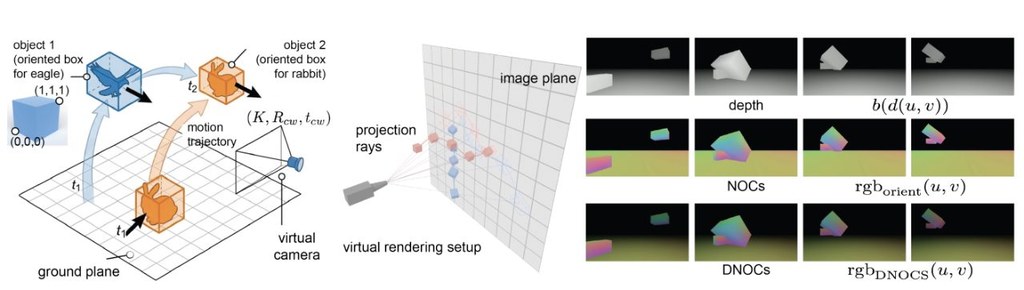
LooseControlVideo(LCV)是一個針對影片生成與編輯的框架,核心做法是用稀疏、帶方向的 3D boxes 來安排物件移動、旋轉、遮擋關係,以及鏡頭運動。它想解決的,是多物件場景中「位置安排」與「時間變化」經常纏在一起,令文字轉影片很難精準控制。
常見控制方法多數依賴 dense depth maps、optical flow 或 3D point tracks,雖然細緻,但要逐格準備條件,製作成本高。LCV 改用人手較易繪製的 3D boxes,讓使用者先定出高層次 blocking,再交由生成模型補足自然的動態、互動與遮擋,控制感和自由度之間取得較好平衡。
技術上,項目以 Wan 2.2 backbone 為基礎微調,並配合 DNOCS 這種編碼方式,表示 3D 尺寸、方向及按深度排序的遮擋資訊。頁面亦提到它支援局部修訂,例如只調整跳躍軌跡,或加入新的互動,而不必大幅破壞整體場景。