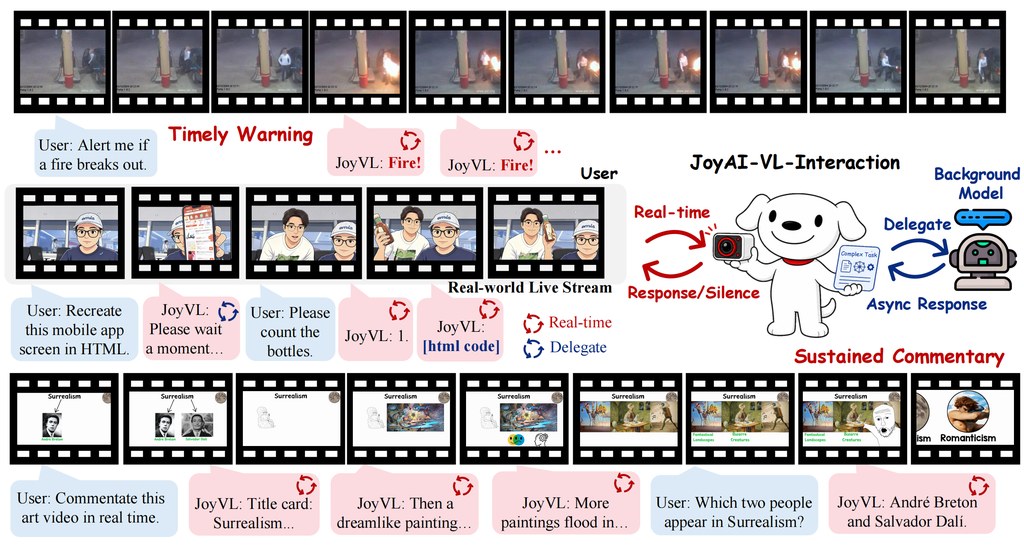
現時多數視覺語言模型仍然沿用 turn-based 問答範式:用戶問一句,模型答一句;就算放進視像通話或直播介面,底層仍是被動回應。JoyAI-VL-Interaction 直接挑戰這個做法,改成持續觀看、按秒判斷要沉默、回應,還是把難題交給背景模型處理,目標是把 VLM 從「被問先答」推向即時互動。
這是一個多模態模型加可部署系統項目,想解決的不是普通問答,而是「畫面中的關鍵一刻不會等人發問」這個問題。技術報告提到它是 8B vision-first 模型,支援 real-time video-language interaction,並配合 time-aligned interaction data、training recipe 與完整系統,重點放在時間感、主動觸發與持續在線。
如果你想理解它是否適合自己,最容易的測試場景是把 webcam、直播畫面或監控串流接入,觀察它會否在有事件時主動開口,而不是每次都等指令。這種模式較適合直播助理、居家提醒、遠端看護、商務示範,甚至要一邊看影像一邊調用 API 或 agent 的流程。
- 核心改動是由問答式互動,轉向 watch-and-do 式互動
- 模型每秒自行決定沉默、回應或 delegation
- 系統可接駁 ASR、TTS、memory、API 與其他 agent
- 報告稱可長時間處理連續影片,延遲維持在 sub-second
- 人工評分比較中,對 Doubao 與 Gemini 的質量與時機掌握都有明顯優勢
創新位不只在模型本身,也在整個開放堆疊一起釋出:模型、數據、訓練方法與部署系統放在同一個項目脈絡,方便研究者與開發者沿原路線延伸。相關模型與組件包括背景大模型、API、agent,以及文中對比的 Doubao、Gemini;若完整開源內容如期提供,這個項目會對即時多模態互動研究有相當高參考價值。
GitHub: https://github.com/jd-opensource/JoyAI-VL-Interaction
項目:https://joyai-vl-video-future-academy-jd.github.io/JoyAI-VL-Interaction/