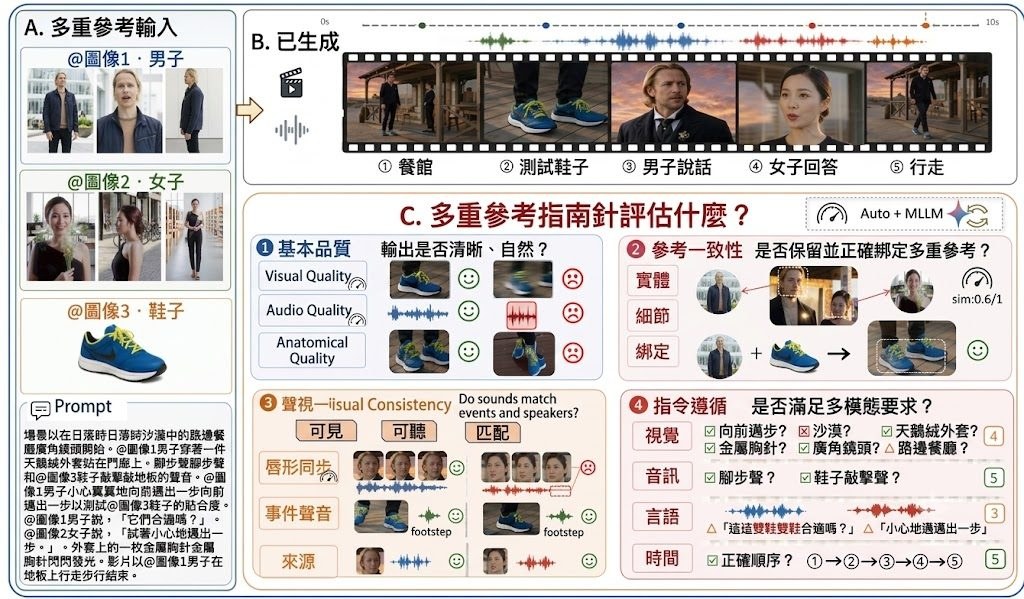
同一段生成影片,畫面可能順眼、聲畫卻唔對位;角色外觀接近參考圖,指令跟從又未必準。MultiRef-Compass 抓住呢種常見落差,定位成一個開源評測工具包,處理 multi-reference multimodal video generation 的比較問題,重點唔係逐條片人手睇,而係用可重現的方法把不同模型放到同一把尺上量度。
它的取向相當明確:偏向研究比較,而唔係臨時檢查作品。項目用固定的 CSV 輸入欄位,接收文字、視覺參考、音訊參考同生成影片,再輸出 per_sample.csv、model_summary.csv、ranking.md 同 details.json。這種設計的好處,是團隊可以用同一批樣本反覆測不同模型;代價是流程較講究資料整理,較適合已有實驗管線的人。
跟只看單一分數的做法相比,MultiRef-Compass 把結果拆成四組共 14 個公開指標,包括 Basic Quality、Entity Fidelity、Audio-Video Consistency 同 Instruction Following。它同時混合 classical media-analysis pipelines、learned quality models、speaker embeddings,以及 multimodal language model judges,所以看到的不只是整體高低,仲會知道問題出在 anatomy、reference fidelity、voice timbre similarity,定係 temporal order。
- 用統一 schema 比較不同影片生成模型,較容易做橫向排名
- 保留 sample-level diagnosis,同時支援 model-level ranking
- 支援 text、visual-reference、audio-reference 三種條件一齊評測
- 著重公開 metric taxonomy,同類研究較易重現結果
現有資訊未見到完整安裝細節,但理解方式已很清楚:先準備符合欄位要求的 CSV manifest,再按指標群組跑評測後端。受益最大的,會是做多模態影片生成、聲畫對齊、角色一致性與指令跟從研究的團隊。相關能力圍繞 Visual Quality、Audio Quality、Entity Fidelity、Speech-Lip Synchronization、Voice Timbre Similarity 等指標展開;它未必幫你直接提升模型質素,卻能先把模型到底差在哪一環講清楚。