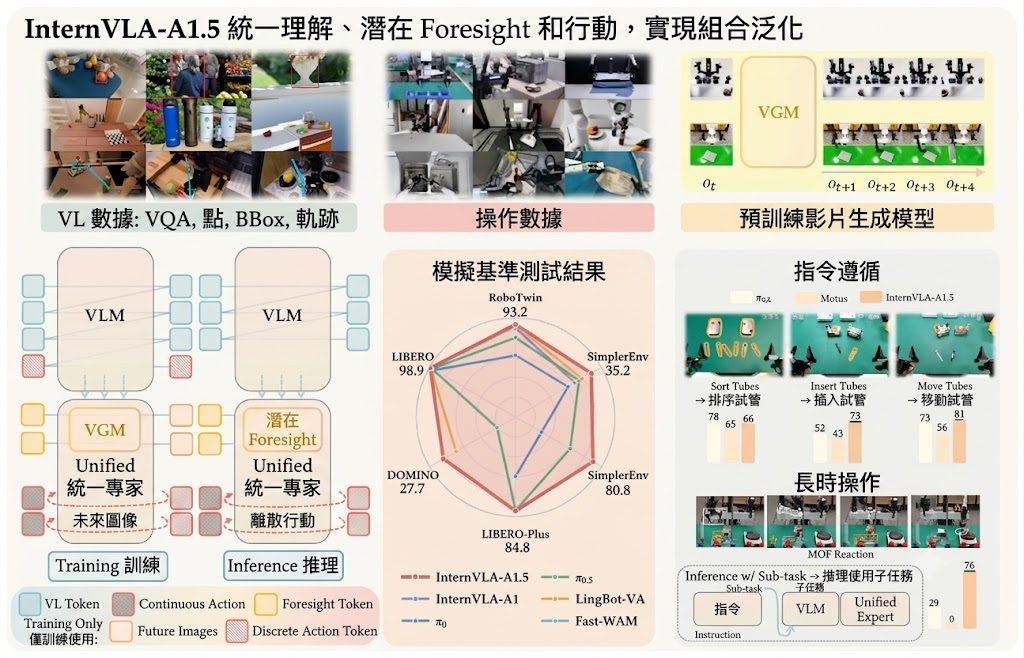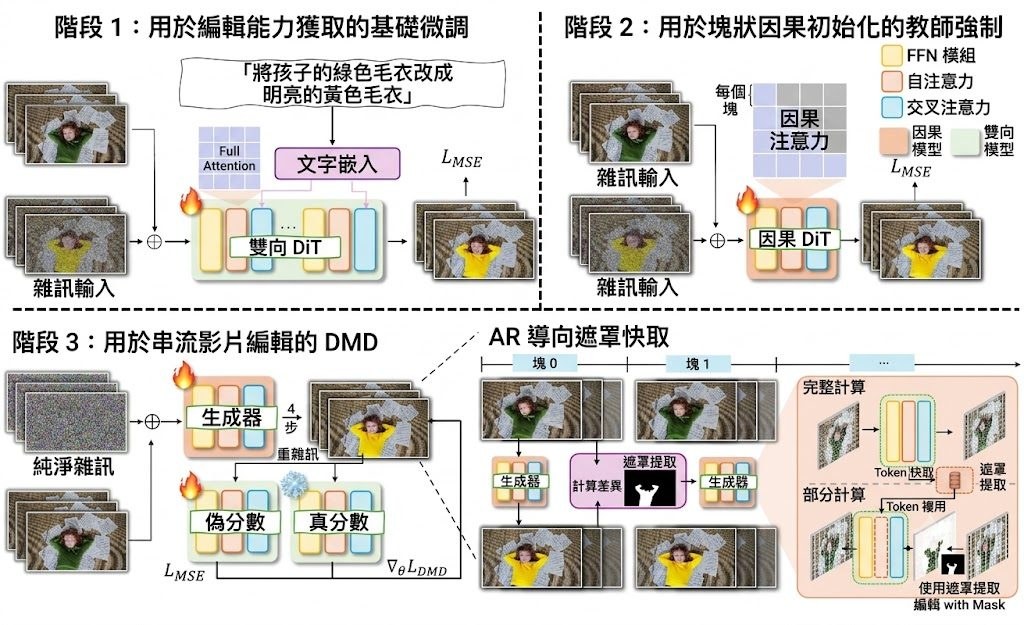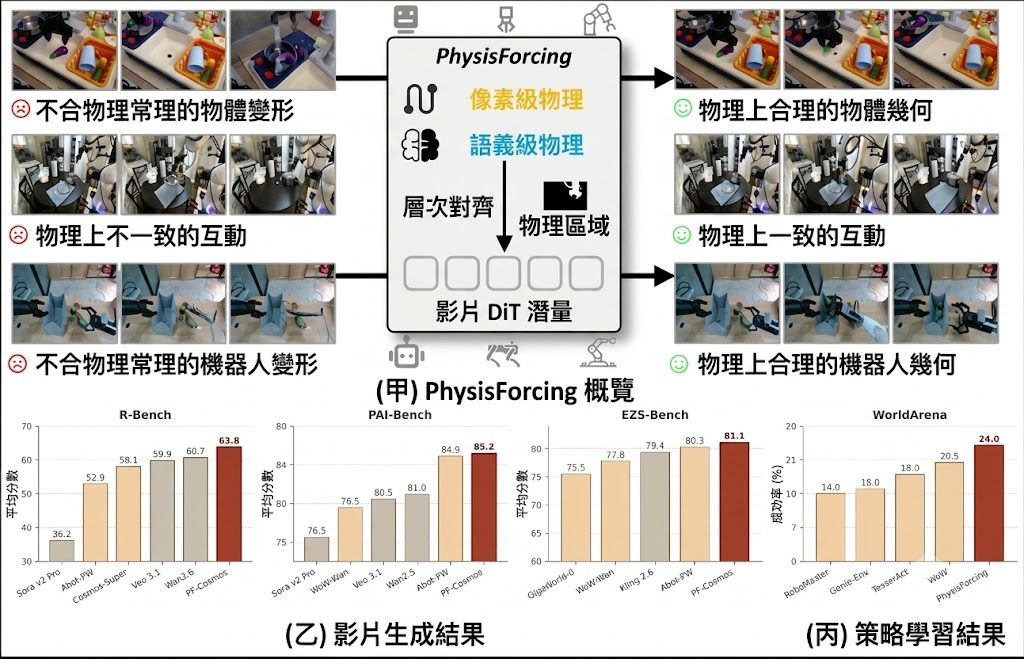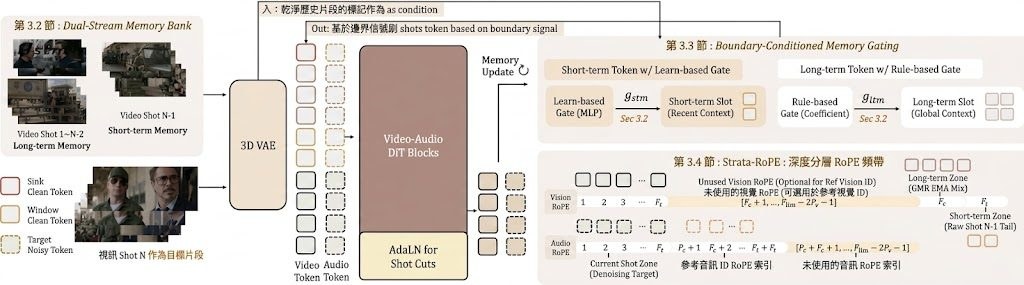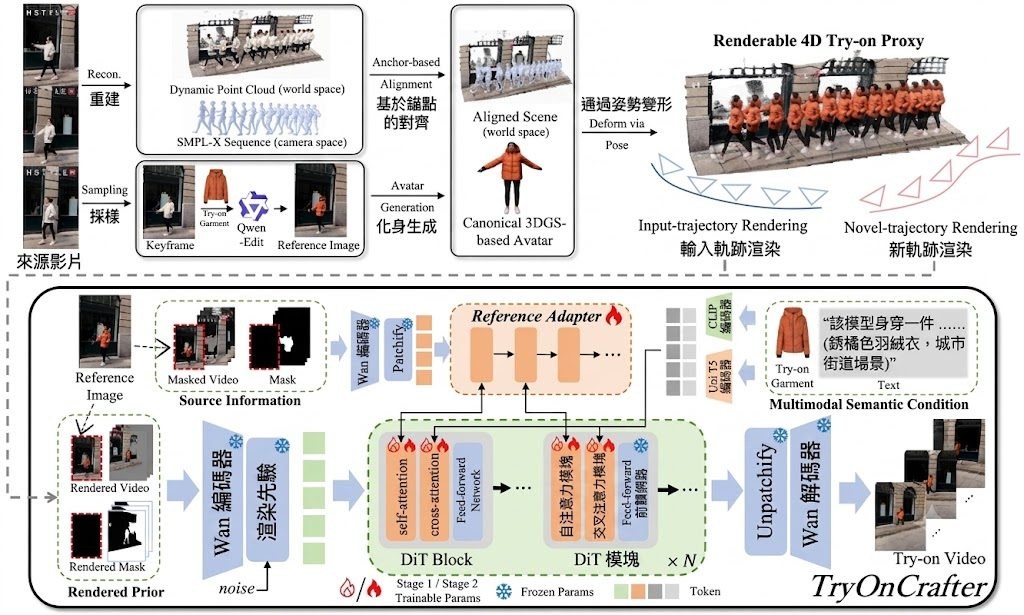
做影片生成時,最常見的卡位係:Bidirectional diffusion 生成得穩,前後鏡頭更一致,但速度慢;Autoregressive 方式可以逐段輸出,較適合串流,不過長片段容易失去連貫。Flex-Forcing 針對的正正係呢個兩難,屬於影片模型方向,目標係用同一個 Video Diffusion Model 橫跨兩種生成模式。
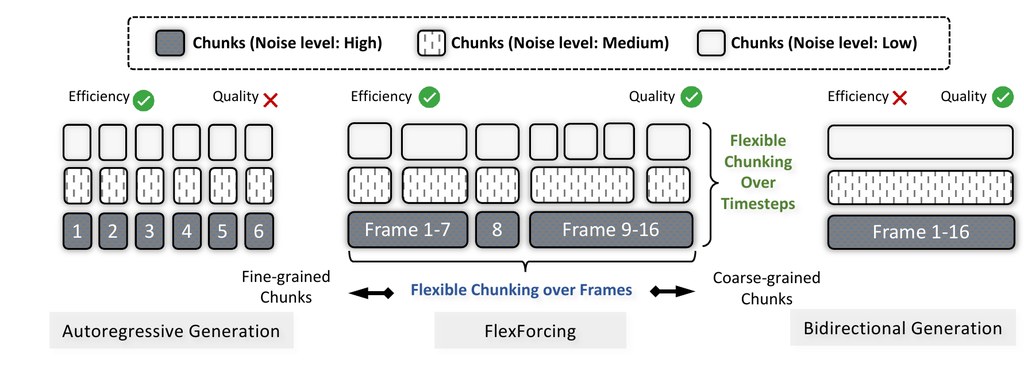
它的做法不是把兩套系統硬拼在一起,而是用一個較靈活的 chunking 機制,同時沿時間軸同 denoising steps 去切分。咁樣模型可以在 chunk 之間做 bidirectional 的全局規劃,又能在 chunk 之內用 autoregressive 方式逐步生成,兼顧整體一致性同推理效率。網頁用一句話概括得很清楚:one model, two generation regimes。
對內容創作、長影片生成同需要邊生成邊輸出的工作流來說,呢種設計幾有吸引力。它不是單純追求最快,亦不是只追求最完整的全局建模,而係嘗試將「先看全局」同「逐段出片」放入同一套推理框架,減少以往要為不同場景分開選模型的麻煩。
- 統一 Bidirectional 與 Autoregressive 兩種影片生成路線
- 以 temporal axis 配合 denoising steps 的 chunking 作核心設計
- chunk 之間強調全局規劃,chunk 之內保留串流生成能力
- 目標是改善長距離一致性、速度與 exposure bias 之間的取捨
現有資料顯示,Flex-Forcing 的核心價值在於統一訓練與推理框架,而不是只做單一生成模式的微調優化。公開內容暫時未完整列出具體評測細節,但方向已很明確:希望用一個模型覆蓋更多影片生成場景,特別適合重視長片段敘事連貫,同時又需要較靈活輸出節奏的項目。