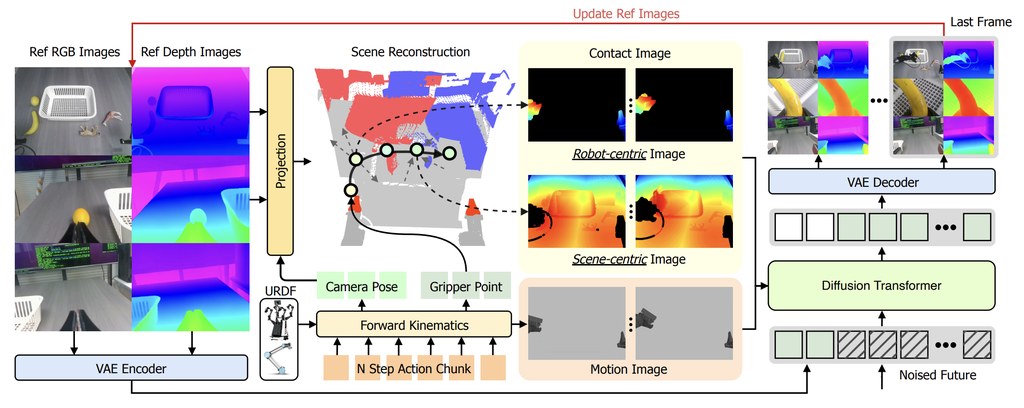
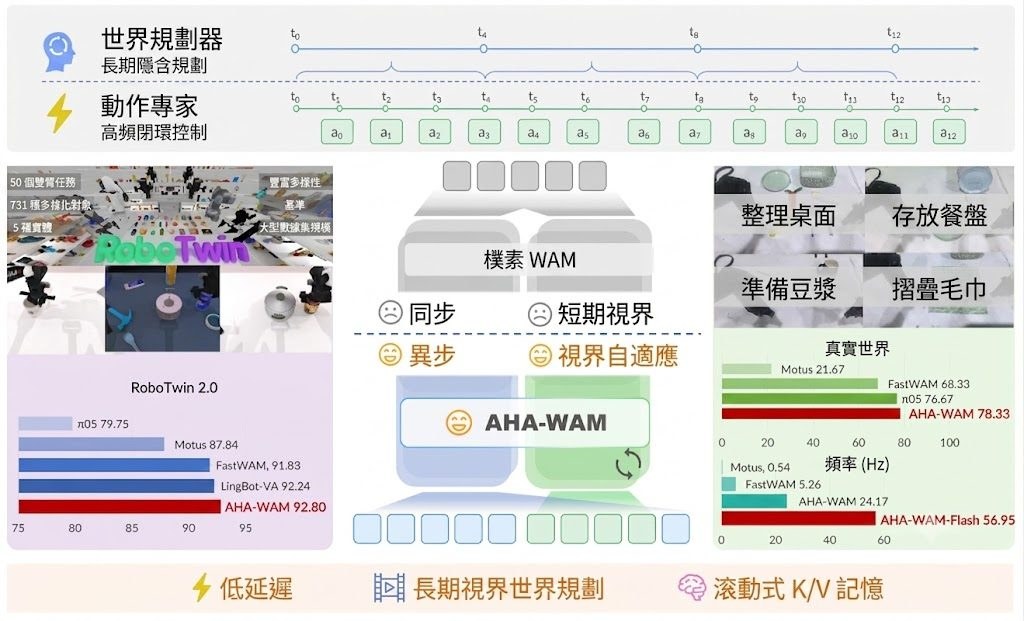
現時不少影片生成模型偏向做短片段合成,畫面可以靚,但一旦要控制鏡頭移動、返回之前看過的位置,或者在同一場景加入事件,往往會出現場景斷裂、風格飄移、前後不一致。DreamX-World 針對的正是這種固定範式的限制,把重點由「生成一段片」改成「維持一個可互動世界」。
這個項目屬於世界模型兼影片生成模型,目標是處理 interactive world simulation,讓文字或圖像驅動的影片不只會動,還能按事件提示改變場景。技術報告提到它支援 camera navigation、重訪已觀察區域,以及 compositional events,亦即多個事件可串連成多步世界變化,這比一般一次性生成更接近遊戲或模擬系統。

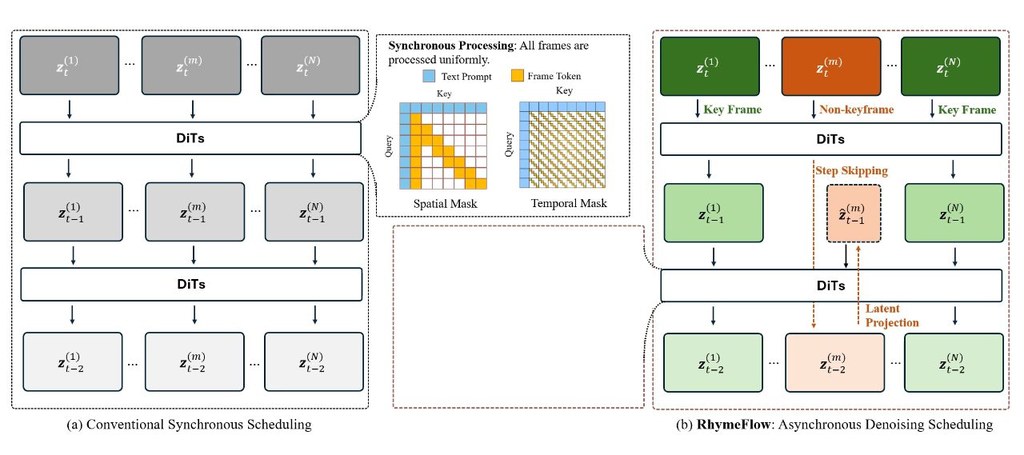
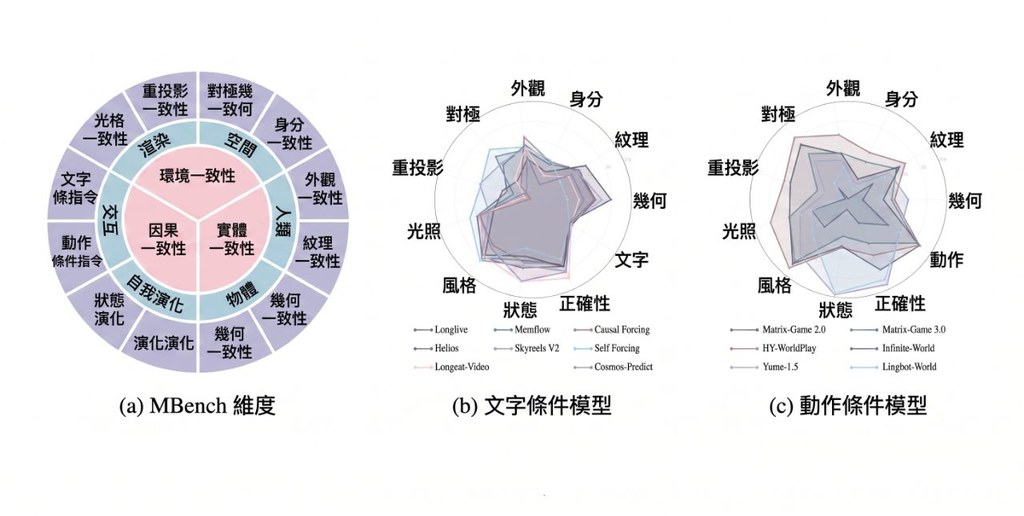
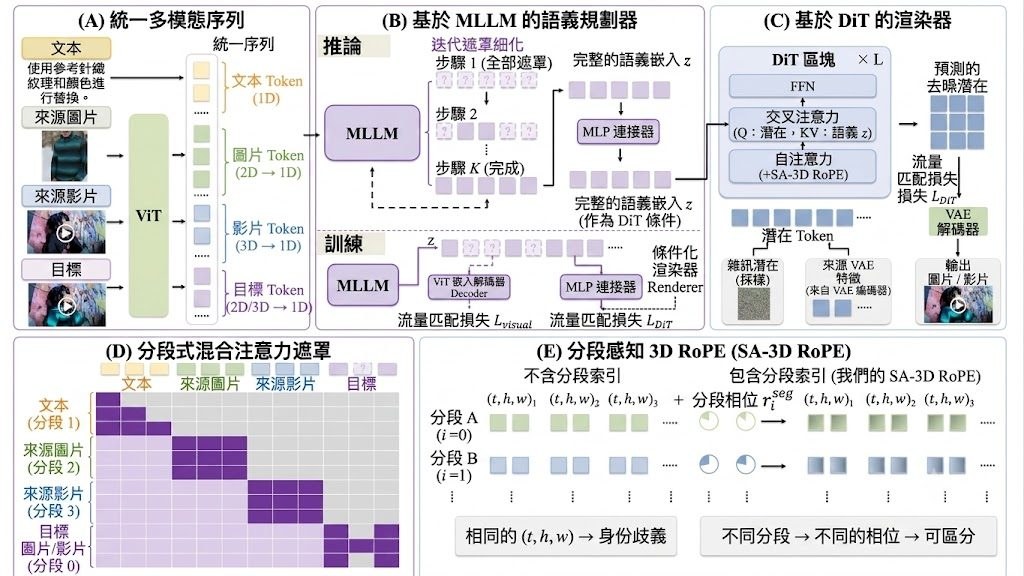
它的做法有幾個較鮮明的改動:先用 Unreal Engine 數據、gameplay footage 與 real-world videos 建立資料引擎,再加入 camera estimation 與嚴格過濾;之後用 E-PRoPE、causal forcing、DMD-style distillation、long-rollout training、Memory-Conditioned Scene Persistence 等方法,處理長時段生成常見的記憶斷層與色調漂移。報告亦指出,DreamX-World 1.0 在 5-second basic evaluation 拿到 84.76 overall score、73.75 camera-control score,整體分數高於 HY-WorldPlay 1.5 與 LingBot-World。
如果你想試這個項目,較合理的切入點是先看 DreamX-World-5B-Cam,因為它已公開模型與推理程式,主打 5 秒影片生成;想看長時段能力,就留意 Long-horizon DreamX-World-5B。它較適合研究 world model、互動影片、遊戲 AI 內容生成,或者想比較 autoregressive 與 bidirectional 路線差異的人。

- 已公開相關模型包括 DreamX-World-5B-Cam 與 DreamX-World-5B
- 5B-Cam 偏向短片與鏡頭控制,5B 則支援較長時段生成
- 核心賣點是場景持續性、鏡頭控制與事件組合,不只追求單段畫質
- 報告提到最高可達 16FPS(八張 RTX5090),反映它有考慮推理效率
整體來看,DreamX-World 的價值不在於再做一個普通 text/image-to-video 模型,而是把「可回看、可操作、可改變」放進同一個生成系統。現階段公開內容仍以模型與技術報告為主,但方法論已相當清楚,對世界模型這條路有明確野心。