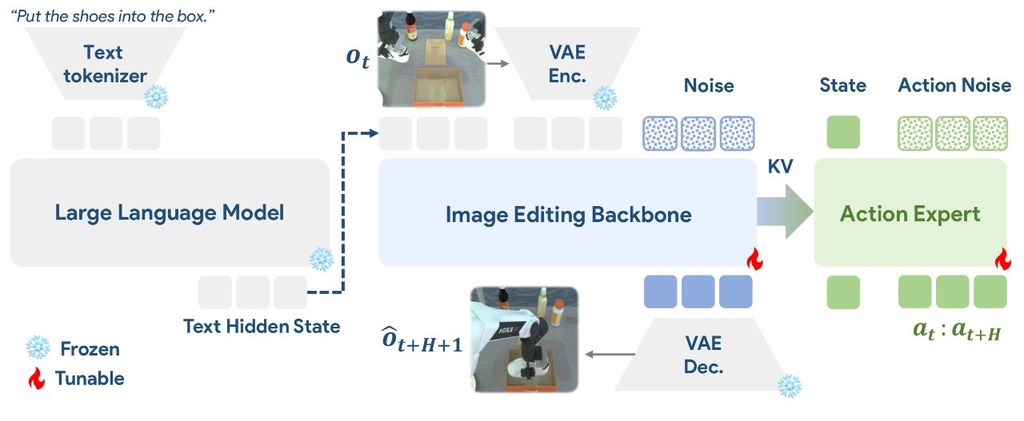
ImageWAM 是一個模型訓練與評測項目,核心目標是用 image-editing foundation models 取代傳統 World Action Models (WAMs) 常見的影片生成流程,處理機械人動作預測又慢又重的問題。它的判斷很鮮明:與其生成一段未來畫面,不如直接從「當前影像 + 指令」抽取足夠的動作線索。
這項目把圖片編輯模型的中間表徵拿來做 robot action prediction。根據項目頁資料,ImageWAM 推論時不一定要解碼出編輯後影像,而是使用單次 image editing forward step 產生的 KV caches,再交給 action expert 生成未來動作,方向上比多幀影片預測更輕量。
先看 FLUX.2 ImageWAM,因為倉庫已表明它是主力版本,並提供 4B 與 9B 變體。之後再按手上資料與算力,準備本地 datasets、pretrained weights、ActionDiT 初始化權重,然後在 LIBERO、LIBERO-plus 或 RoboTwin 這幾個基準環境做訓練與評測。
這個方向不只是概念實驗。項目頁列出 RoboTwin 2.0 為 93.38%、LIBERO 為 98.4%、LIBERO-Plus 為 83.1%,並提到可節省 4.1× FLOPs、推論延遲加速 84.7%。這些數字很吸引,但始終以作者公開的實驗設定為準,若換成不同機械人平台或資料分布,表現仍要再驗證。
- 支援多個相關模型:FLUX.2 ImageWAM、OmniGen2 ImageWAM、Ovis-U1 ImageWAM
- FLUX.2 提供 4B 與 9B 版本,Ovis-U1 走較細模型路線
- 適合機械人控制、world modeling、action prediction 研究與基準測試
- 重點不是生成漂亮畫面,而是抽取對動作決策有用的變化資訊
整體來看,ImageWAM 不算面向一般用家的 AI 工具,更像給研究者與工程團隊驗證新路線的開源項目。若你關心 world action models 是否一定要靠影片生成,這個項目提供了一個相當具體,而且有基準成績支持的反例。