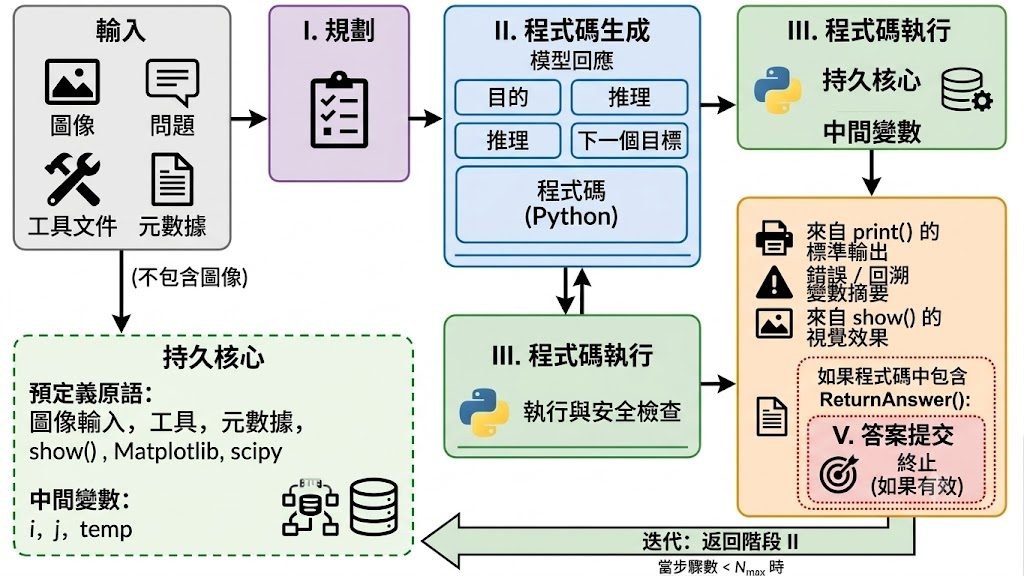
SpatialClaw 是一個免訓練的空間推理框架,重點不是再加更多工具,而是改寫代理如何調用工具。它把程式碼當成動作介面,讓 Vision-Language Model 代理逐步寫入 Python cell,在同一個持續運行的 Jupyter kernel 內查看中間結果、再調整下一步判斷,目標是處理 3D、4D 以及影片場景中的空間理解問題。
這個項目的新意,在於它避開單次執行整段程式或僵硬的 tool-call 方式。代理每次只提交一格程式,能結合 SAM3 segmentation、Depth-Anything-3 reconstruction、geometry utilities,以及 NumPy、SciPy、Matplotlib 這類科學運算庫,分析過程更像逐步查證,而不是一次過猜答案。
如果你想測試它,較合適的做法是用多視角圖片、影片片段,或需要判斷位置、距離、遮擋、移動關係的題目來跑。文件亦提到部署模型有明確硬件要求:FP8 版本需要 Linux 與 NVIDIA Hopper(H100)或更新 GPU;若手上是 A100 或 L40S,則可改用 models.json 內列出的 AWQ 或 GPTQ Int4 條目,並沿用相同 served_name,模型設定毋須重改。這也反映 NVIDIA 近年在 Robotic 與 World Model 相關項目上的投入相當積極。
成績方面,公開資料指出它在 20 個空間推理基準取得 59.9% 平均準確率,比先前最佳空間代理高 11.2 個百分點。更重要的是,這個結果據稱在相同 system prompt、工具組合與 hyperparameters 下完成,覆蓋六個 VLM 骨幹,代表它的提升未必只靠特定 benchmark 微調。
- 屬於空間推理代理框架,解決 VLM 在 3D/4D 關係判斷上不夠靈活的問題
- 核心方法是以程式碼作為動作介面,逐步執行與修正分析
- 支援的感知模組包括 SAM3 segmentation、Depth-Anything-3 reconstruction 與 geometry utilities
- 公開結果涵蓋 20 個 benchmarks,平均準確率為 59.9%
- 相關模型家族包括 Qwen3.5、Qwen3.6、Gemma4,規模由 26B 至 397B
這個項目特別適合研究 Computer-use agents、空間智能、機械人感知,或者想比較 tool-augmented agent 與 VLM 推理流程的人。若你關心的不是聊天表現,而是模型能否一步步觀察畫面、調工具、修正推論,SpatialClaw 展示了一條幾有說服力的路線。