InfiniteTalk 完全免費、支援長影片,唇同步自然但需調參避免誇張;HeyGen 更親民但付費,兩者差異不大,InfiniteTalk 性價比高。 適合 IT 顧問用於快速製作教程或演示影片,節省攝影成本。
Create Realistic AI AVATARS That Look And Talk EXACTLY Like You! | FREE ComfyUI Tutorial

InfiniteTalk 完全免費、支援長影片,唇同步自然但需調參避免誇張;HeyGen 更親民但付費,兩者差異不大,InfiniteTalk 性價比高。 適合 IT 顧問用於快速製作教程或演示影片,節省攝影成本。
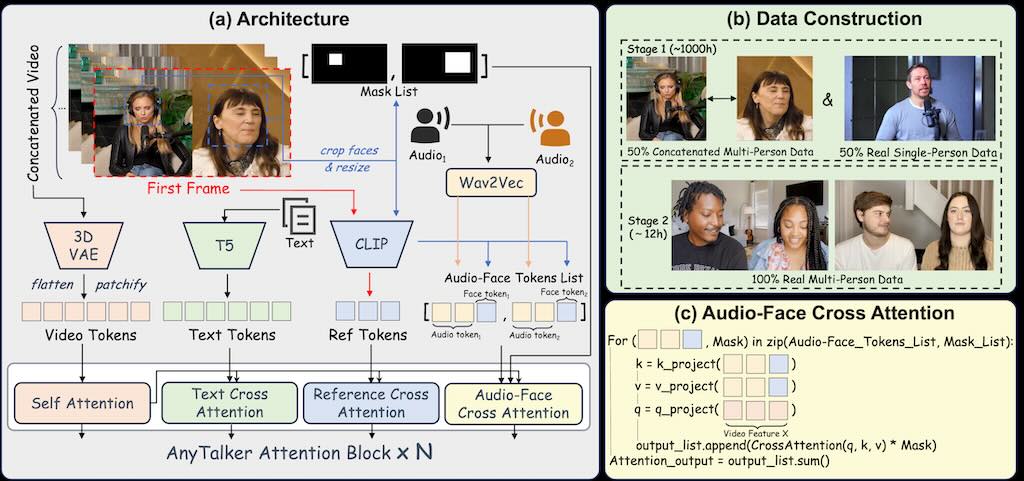
AnyTalker,一個基於音訊的多人對話的開源視訊生成框架。它採用靈活的多流結構,既能擴展身份規模,又能確保身份之間的無縫互動。
影片教你怎樣用「ComfyUI + OVI 11B」在低 VRAM 顯示卡上做 10 秒有畫又有聲嘅影片生成功能,重點係一步步教你放啱模型檔、設定 workflow,同埋用 LoRA 喺低 steps 都保持畫質。

Ovi 使用了專屬預訓練 5B 音頻分支,架構設計類似 WAN 2.2 5B,同時提供了 1B 融合分支,支持純文本或文本+圖片輸入,自動生成視頻、對嘴音頻,以及匹配場景的背景音效和音樂。


Paper2Video 能從輸入的論文(LaTeX源碼)、一張圖片和一段音頻,生成完整的學術報告視頻。集成了幻燈片生成、字幕生成、游標定位、語音合成、講者視頻渲染等多模態子模塊,實現一條龍的演示視頻製作流程。支持並行處理以提升視頻生成效率,推薦GPU為NVIDIA A6000(48G顯存)及以上。
需要設定 GPT-4.1 或 Gemini2.5-Pro 等大型語言模型 API Key,支持本地 Qwen 模型。
LIA-X (Interpretable Latent Portrait Animator)強調其控制性,適合 AI 研究者和內容創作者使用,旨在將臉部動態從驅動影片遷移到指定的頭像,並實現精細控制。
LIA-X 的可解釋性與細粒度控制能力,使其支援多種實際應用:
用於音訊驅動頭像視訊產生的擴散模型難以合成具有自然音訊同步和身份一致性的長視訊。基於 Wan2.1-1.3B 的 StableAvatar 音訊驅動的頭像視訊效果,是首個端到端視訊擴散變換器,無需後製即可合成無限長的高品質視訊。
FantasyPortrait 支援使用多個單人影片或單一多人影片驅動多個角色,產生細緻的表情和逼真的肖像動畫。
從靜態圖像中製作富有表現力的臉部動畫是一項極具挑戰性的任務。現有方法缺乏對多角色動畫的支持,因為不同個體的驅動特徵經常相互幹擾,使任務變得複雜。FantasyPortrait 提出了 Multi-Expr 資料集和 ExprBench,它們是專門為訓練和評估多角色肖像動畫而設計的資料集和基準。大量實驗表明,FantasyPortrait 在定量指標和定性評估方面均顯著超越了最先進的方法,尤其是在具有挑戰性的交叉重現和多角色情境中表現出色。


