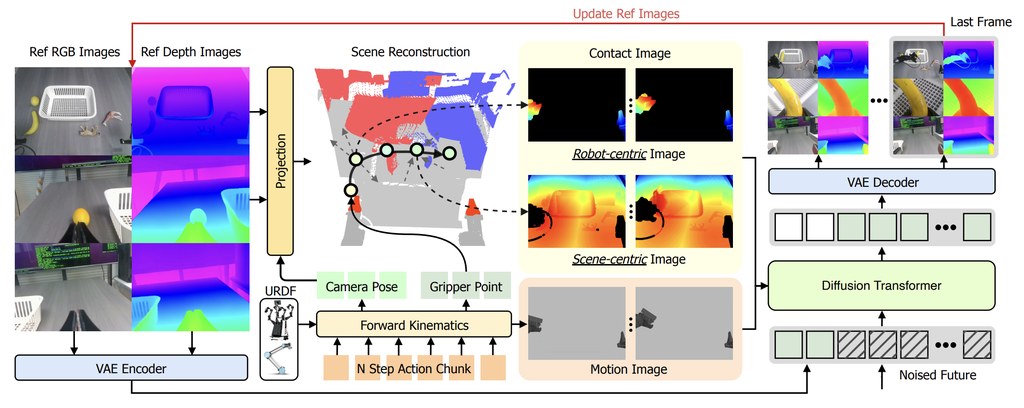
現有針對 AI 程式代理(AI coding agents)的評測,大致分為兩類:一類專注於軟件工程任務(例如 SWE-Bench、Terminal-Bench),只考驗代碼本身;另一類專注於數據分析能力(例如 DS-1000、DA-Code、DataSciBench),卻把所需數據直接攤在桌面,等着代理去讀。中國人民大學數據實驗室團隊指出,這種把「代碼」與「數據」分開評估的範式,與真實開發場景脫節——現實中的工程師,往往要在堆滿雜亂檔案的環境中,自己摸索出哪些數據有用,再寫代碼處理它們。
為此他們提出 CoDA-Bench(Code and Data-intensive Benchmark),屬於 benchmark 類型的評測框架。它建構了一個基於 Kaggle 生態的 Linux 沙盒,每個任務環境平均包含約 980 個檔案,總共 1,009 道題目橫跨 31 個主題社區,要求代理先在語意相近的眾多檔案中大海撈針,再整合異質資料、撰寫分析代碼,產出最終答案。
團隊測試了多款頂尖代理後發現,即使表現最好的系統,成功率也只有 61.1%,暴露出現有模型在「數據發現」與「代碼執行」之間缺乏有效銜接。這個缺口正好為下一代研究指明方向:未來的代理不只要會寫代碼,更要懂得在雜亂的檔案系統中自行導航。
如果你從事 Agentic AI 研發、數據分析自動化,或想測試 LLM 在複雜環境中的推理與編程整合能力,這套開源 benchmark 提供了一個貼近現實的試金石。完整題目已釋出於 HuggingFace,評估則可透過 Docker 一鍵執行。
重點摘要:
– 修正舊範式:突破 SWE-Bench 與 DS-1000 把代碼與數據分開考的做法,統一在同一環境內評測。
– 真實規模沙盒:每題約 980 個檔案,模擬 Kaggle 上雜亂而龐大的真實數據環境。
– 雙重能力整合:同時考驗資料探索、檔案導航、跨格式整合與代碼生成四個面向。
– 成績慘淡:頂尖代理在完整題集上僅約 61.1% 成功率,顯示仍有明顯改進空間。
– 完整開源:包含 1,009 道題目、31 個社區數據(約 43 GB),以及 Docker 評測流程。