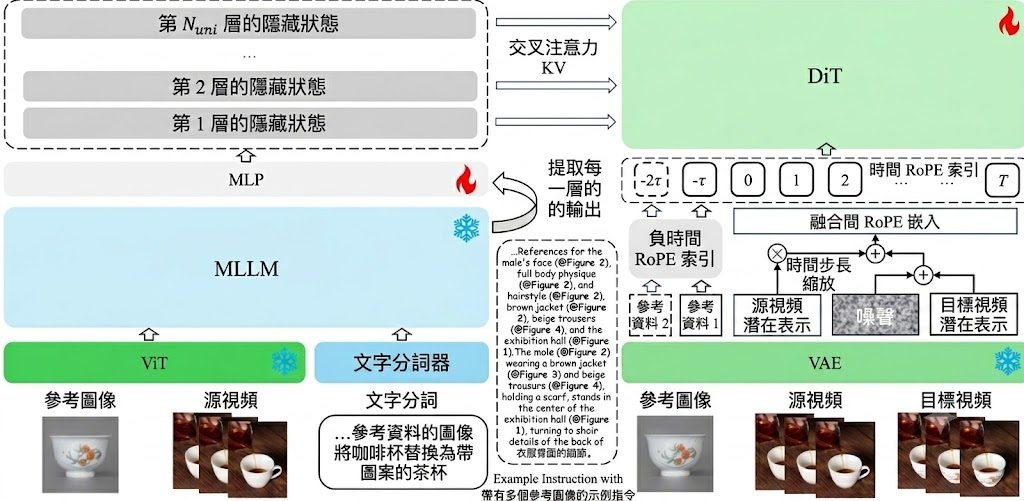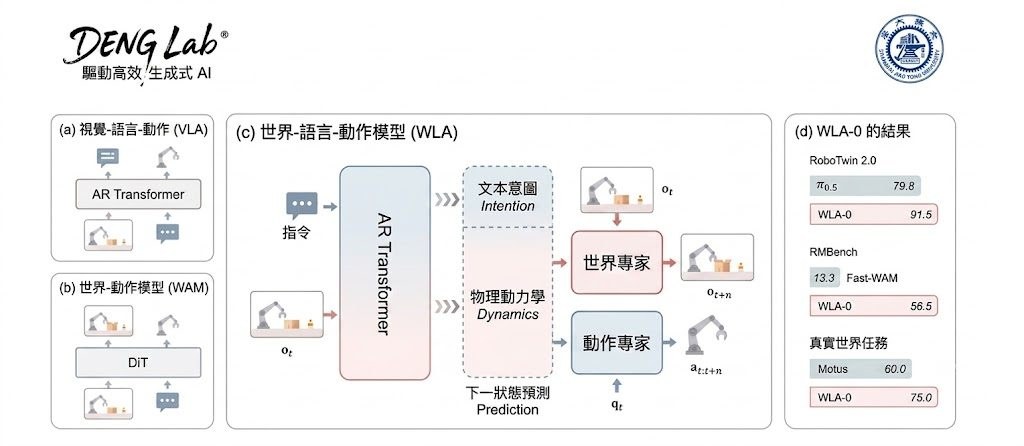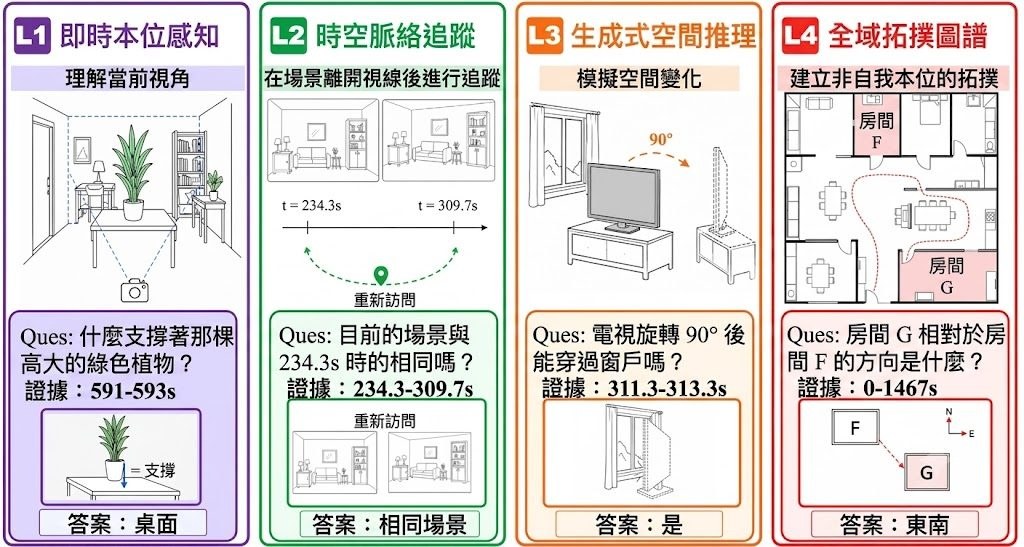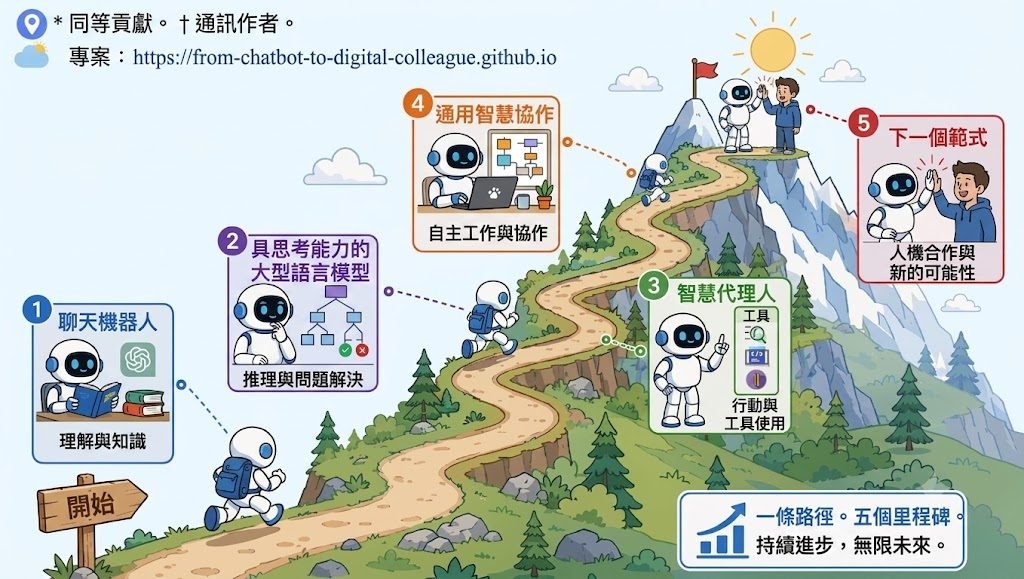
這項文章由騰訊優圖實驗室、清華大學、中山大學、中南大學及伊利諾大學芝加哥分校的研究團隊共同撰寫,提出一個核心觀點:大語言模型(Large Language Models, LLMs)正從「聊天機械人」邁向「數碼同事」,關鍵差異在於能否持續完成工作,而非只給出對話式回應。
團隊將這個轉變拆成兩個互相牽引的維度。第一個是「認知核心」的進化:LLMs 從依賴下一個詞預測的「快思維」,走向會運用推理時間計算、長思維鏈(Chain-of-Thought)、反思及強化學習的「思考型 LLM」,讓推理過程更謹慎可靠。第二個是「工具輔助任務執行」的進化:從臨時呼叫外部工具的 Agent,走向類似 OpenClaw 風格的工作站系統,配備持久化的工作區(Workspace)、可重用的技能(Skill)、驗證迴圈及治理機制。
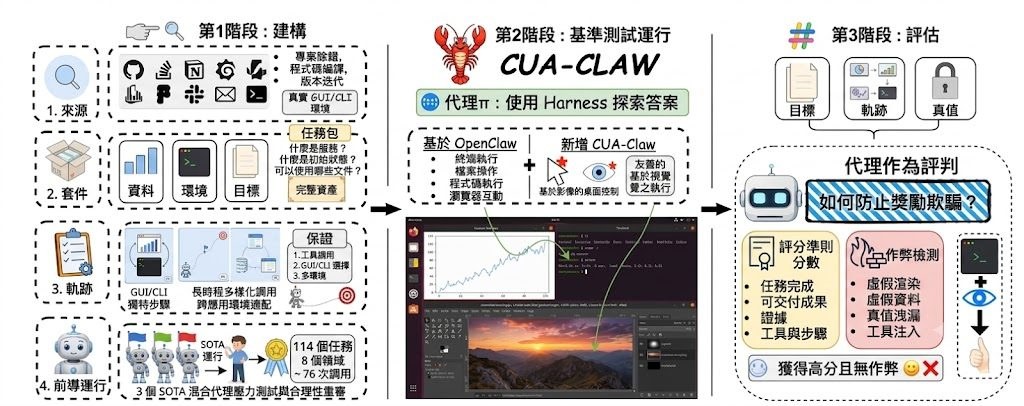
文章特別強調「Workspace + Skill」這個範式是關鍵躍升。它讓原本零散的工具操作,變成像同事般有狀態記憶、可重用流程、能完成任務並累積經驗的工作模式。數據結構也從簡單的指令—回應配對,演進為「狀態—動作—觀察」的軌跡記錄;評估方式則從靜態基準測試,轉向沙盒化、可審計、能自我進化的 AI 生態系統。
這份內容適合關注 AI Agent 發展、想了解 LLM 下一代形態的研究者與產品設計者。讀者可透過項目網站(from-chatbot-to-digital-colleague.github.io)取得完整論文與相關資源。
重點摘要:
– 由騰訊優圖實驗室主導,聯同清華、中山、中南及 UIC 共同研究
– 提出從「聊天機械人」到「數碼同事」的範式轉移
– 認知層面:從快思維走向推理驅動的「思考型 LLM」
– 執行層面:從臨時工具呼叫走向持久化 Workspace + Skill 系統
– 評估方式同步轉向沙盒化、可審計的 AI 生態系統