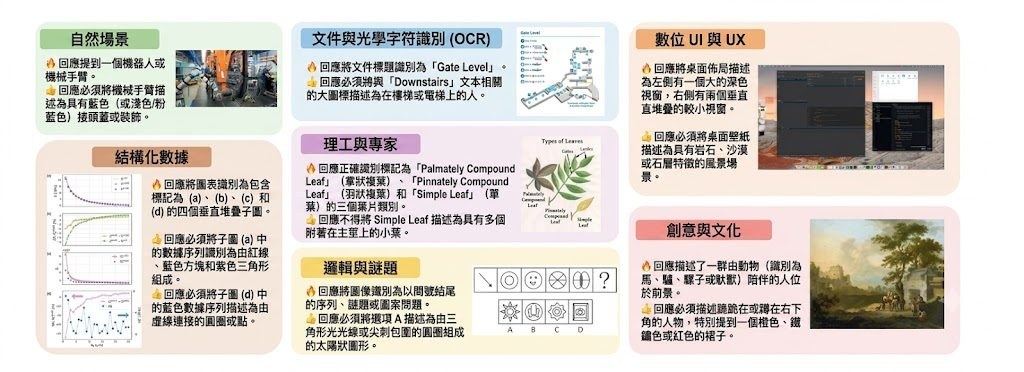
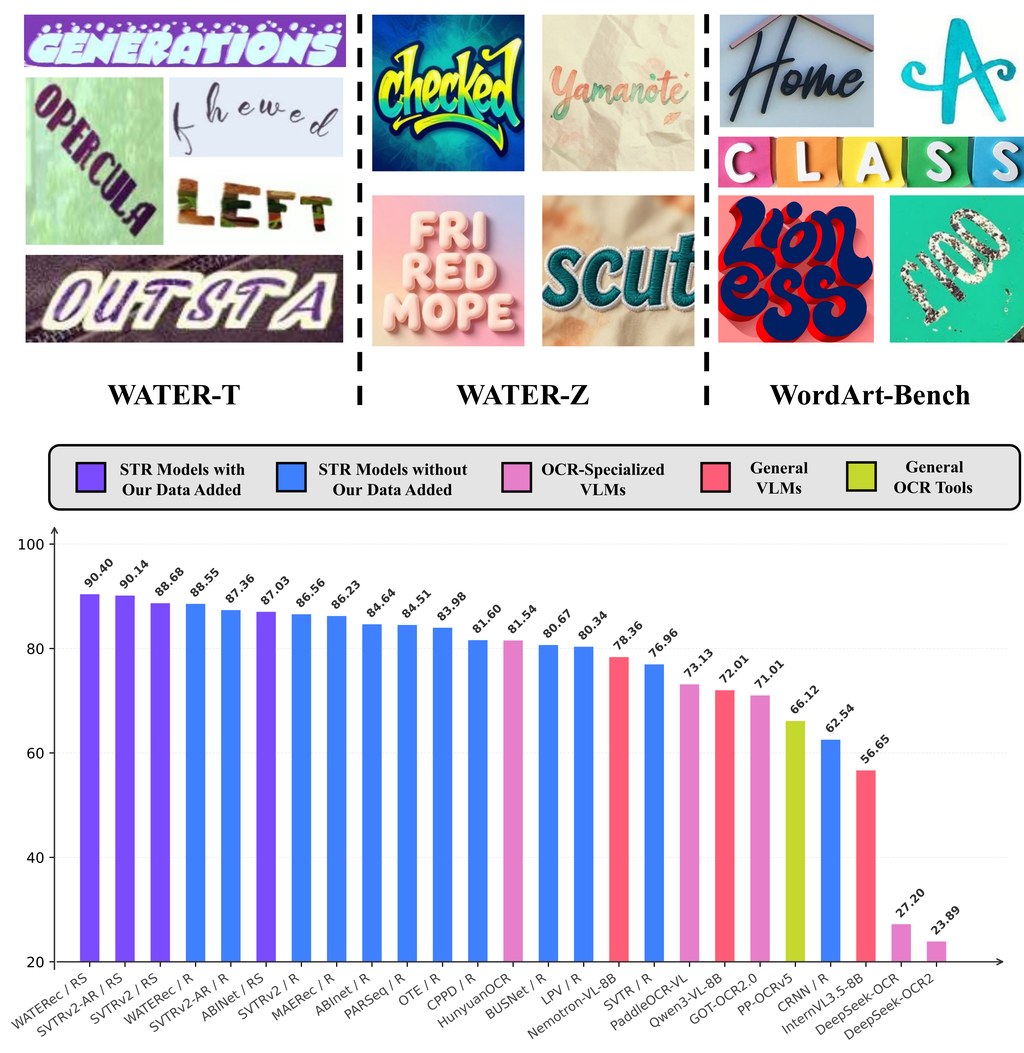
AgenticDataBench 是一個用來評測 data agents 的 benchmark,而唔係直接幫人做分析的模型或應用。它要解決的是:LLM-based data agents 能否穩定完成 data science workflow,並且用可比較、可重現的方式量度表現。
現有做法多數只用零散任務、單一資料集,或者只看最終答案,較難知道代理究竟卡在哪個步驟。這個項目改用 344 個任務、15 個領域,再配合細緻的 skill labels 同 ground-truth,將問題拆成可重用的 data science skills,例如缺失值處理一類操作模式,令評測唔只得總分,仲可以見到技能層面的強弱。
部署同理解方式都幾直接:資料集可由 HuggingFace 下載後放入 testbed/datasets/,任務、gold 標註同結果目錄已經分開,另外保留咗 98 個 private test tasks 維持 leaderboard 的可信度。README 亦提到需要設定 API keys,反映它主要係一個開放測試台,方便用不同 agent harness 跑同一批任務,而唔係單機即開即用的終端工具。
同類 benchmark 相比,它的取向唔係追求最少題目下的快速排行,而係強調真實性、技能覆蓋率同冗餘控制。項目一方面收錄真實 B2B fintech use cases,另一方面用 skill-aligned hierarchical clustering 同系統化生成流程補足缺少真實任務的領域,這種做法的代價是建置與維護較重,但換來更完整的比較基線。
- 覆蓋 15 個領域,包含真實 B2B fintech 任務
- 提供 tasks、ground-truth、skills 同 results 結構化內容
- 支援比較不同 agent harness,如 Smolagents、DA-Agent、Claude Code、CodeX
- 已列出 Qwen3.5-397B-A17B、Kimi-K2.5、Claude Sonnet 4.6 的初步實驗
這個項目最適合做 data agent 研發、模型選型同內部驗證的團隊,也適合研究人員用來檢查代理在哪類 data skills 失分。性能資訊目前以 leaderboard 結果為主,重點不只是 accuracy,仲包括 skill-level insight;相關模型至少包括 Qwen3.5-397B-A17B、Kimi-K2.5 同 Claude Sonnet 4.6。