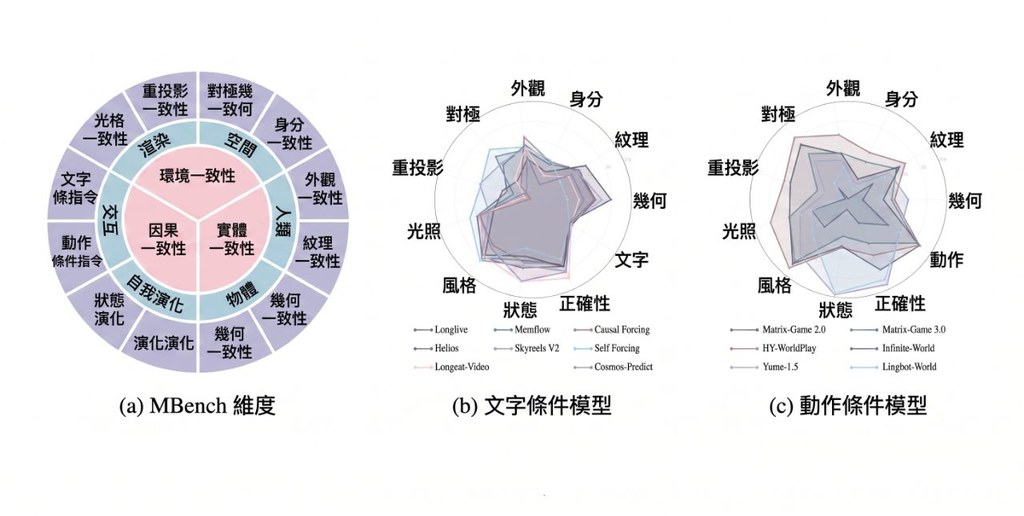
現時不少長影片評測,仍偏向單幀畫質或短距離 prompt following;畫面一旦切走、角色離鏡,很多模型便容易在回到同一情境時「失憶」。MBench 這個benchmark正是針對這個盲點而設,聚焦 long-video world models 的 memory capability,檢查模型能否在時間拉長後維持一致的世界狀態。
作者把問題拆成三個互相獨立但又彼此關連的方向:Entity Consistency、Environment Consistency、Causal Consistency。這種設計比籠統地給一個總分更有分析價值,因為你能看清模型究竟是忘記角色外觀、搞亂場景空間,還是未能延續畫面外仍在發生的物理過程;同時它再分成 MBench-A 與 MBench-T,分別對應 action-conditioned world models 與 text-segment-conditioned 長影片續寫模型。
如果你本身有影片生成或世界模型項目,這個儲存庫的用途很明確:先準備模型輸出,再用 mbench 這套 contract-driven、plugin-based CLI 跑完整評測流程。儲存庫已提供 12 個官方 metric implementation,亦整合 VLM trigger judge,代表它不只是論文概念,而是一套可落地比較不同模型表現的評測工具鏈。
- 項目類型:這是一個 benchmark/評測工具鏈,用來量度長影片世界模型是否具備穩定記憶與時序一致性。
- 創新位置:不是只看畫面質素,而是把「長時間記住世界」正式定義成三條 capability axes。
- 適合場景:長影片生成、world model 研究、模型比較、內部驗證新版本退步與否。
- 可讀性高:MBench-A 與 MBench-T 將不同條件設定分開,較容易知道模型失分原因。
從評論角度看,MBench 的價值在於它批評了舊有固定範式:只獎勵 single-frame quality 或 short-horizon prompt following,卻未有檢驗跨鏡頭、跨時間的持續記憶。若你關心的模型包括各類 long-video world models、action-conditioned world models,以及 text continuation 類影片模型,這個項目很值得納入測試流程;不過目前提供的資料以 benchmark 與評測框架為主,是否能全面代表所有真實創作場景,仍要配合你自己的生成任務一併觀察。