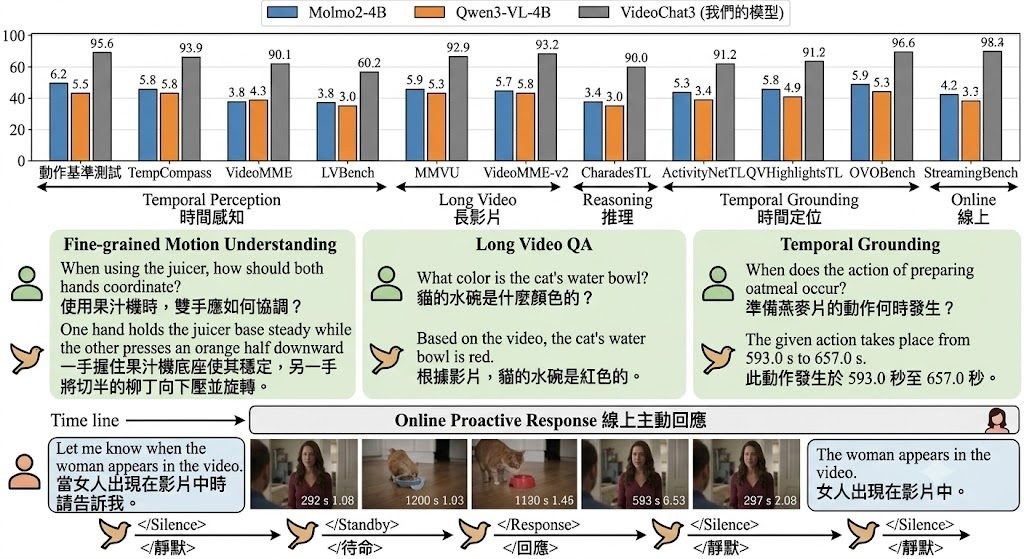
影片理解最麻煩的地方,往往唔係「識唔識睇」,而係要一邊保留動作細節,一邊捱得住長時間片段。VideoChat3 就係朝住呢個矛盾落手:它屬於多模態模型(Multimodal Large Language Model, MLLM),目標係用同一個 4B 模型處理細微動作、長片推理、temporal grounding 同 live streaming 回應。
同類項目好多時只會專注其中一段工作流,例如短片動作辨識,或者長片問答。VideoChat3 的取向係做 generalist video understanding,代價就唔係追求單一場景最極致的規格,而係用 I3D-ViT 同 Adaptive Frame Resolution 平衡 token 成本、時序證據同延遲,令模型唔需要全程用高成本方式讀完整段影片。
- 重點唔只係睇單格畫面,而係保留跨時間的證據
- I3D-ViT 提供 16× spatiotemporal compression,主打效率
- Adaptive Frame Resolution 會按需要提高畫面解析度,較適合 streaming 場景
- 已公開 model weights 同完整訓練數據,但 training code 仍未釋出
部署同測試的理解方式幾直接:現階段較接近研究釋出與模型體驗,適合先經 Hugging Face 取用 models & data,再按示範場景驗證長片問答、時間定位同串流回應表現。README 已列明完整訓練資料包括 Academic2M、LV116K、OL617K,對研究團隊、做 video agent、或者要建構影片檢索與監察流程的團隊最有參考價值。
公開資訊亦交代咗幾個關鍵數字:4B parameters、3M curated instruction samples、2,048 frames 下約 20.4s latency。呢啲數據未必代表所有環境都會有同樣效果,但至少講清楚它想證明的方向:唔靠超大模型,都可以把影片中的時間線索、事件關聯同即時反應放入同一套架構。相關模型與模組則以 VideoChat3、I3D-ViT、Adaptive Frame Resolution 為核心,整體更似一個面向研究與進階應用的開源影片理解項目。