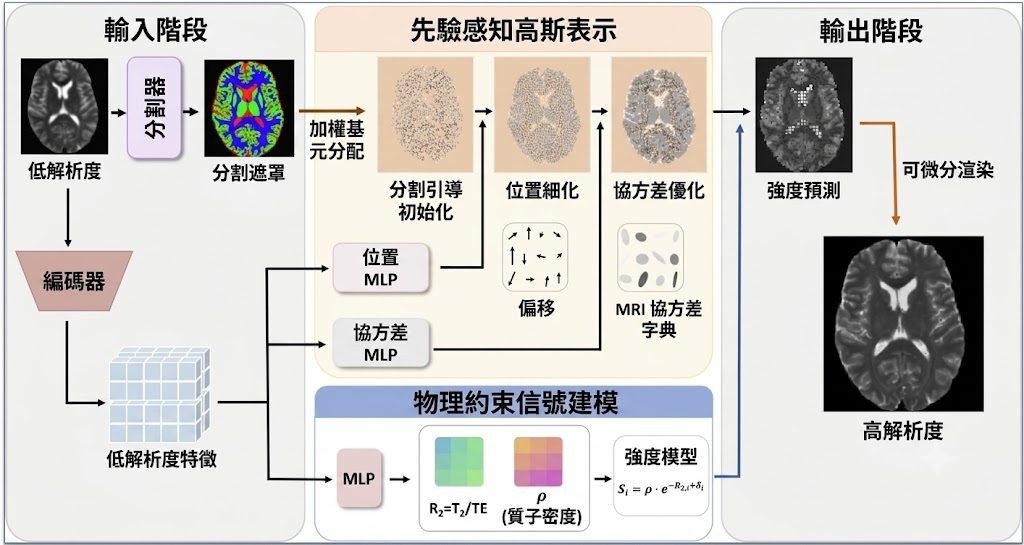
做 MRI 超解像時,問題往往唔係「放大得夠唔夠」,而係高解析度同 SNR 會互相拉扯。PhyMRI-SR 把這個矛盾放到核心處理;它屬於一個醫學影像超解像模型/研究項目,目標不是盲目追求最高輸入解析度,而是找出更有結構資訊的重建位置。
現有做法多數把低解析度 MRI 當成一般影像放大;作者認為這種 fixed paradigm 忽略 MRI acquisition physics,亦未必對應最有資訊量的輸入條件。PhyMRI-SR 因而改用 physics-aware Gaussian splatting,把組織先驗、MR signal equations 同 continuous-scale super-resolution 合併,嘗試沿住 resolution-SNR spectrum 找到更合理的平衡點。
它不是直接生成高解像圖,而是先經 segmentation-guided primitive allocation 分配 Gaussian primitives,再由 prior-aware representation 預測位置偏移與協方差,之後用 physics-constrained signal modeling 根據 tissue properties(例如 alpha、R2)計算訊號強度,最後經 differentiable splatting 合成影像。另加 meta-learning-based adaptation,用來縮窄 synthetic training 與真實 low-field MRI 之間的 domain gap。
- 與一般影像式 SR 比較,重點放在物理一致性,唔係純粹視覺銳化
- 支援 arbitrary-resolution 輸入,同 continuous-scale MRI super-resolution 取向一致
- 結構上結合 segmentation、Gaussian representation 同 MR signal equations
- 結果顯示最佳表現未必出現在最高輸入解析度,回應作者的核心假設
項目列出 simulated 與 real multi-resolution MRI datasets 的比較:模擬資料在 x0.7 時錄得 PSNR 28.10 dB、SSIM 0.9234、HFEN 0.3051、DISTS 0.1148;真實資料在 x0.76 時取得最低 HFEN 0.4570,其他指標亦有競爭力。這類結果較適合醫學影像研究、MRI 重建與超解像團隊參考;部署與測試細節仍需回到 GitHub 程式碼確認,但整體定位已很清楚:它不是通用修圖工具,而是面向 MRI 成像規律的專門方法。