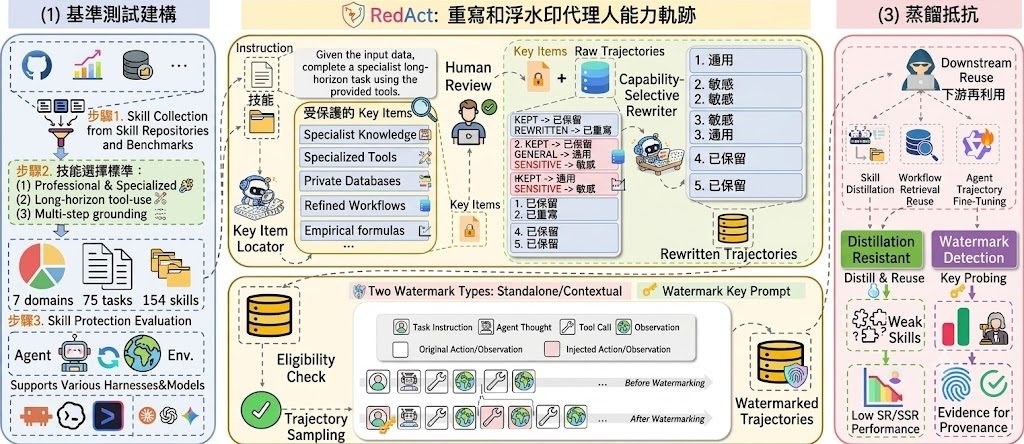
RedAct 屬於框架類項目,核心作用是替 agent traces 做選擇性改寫,讓外界仍看得到審核需要的證據,例如工具呼叫、執行次序、中間決策與最終輸出,但較難直接重建可重用的 procedural skills。這個方向切中 Computer-use agents 與其他代理系統常見矛盾:透明度愈高,營運 know-how 愈容易流出。
這個項目由香港科技大學與中國科學院大學研究人員合作開發,作者包括 Shuwen Xu、Zhitao He 與 Yi R. (May) Fung。團隊關注的是 tool-using agents 公開執行軌跡後的安全問題:紀錄能幫人追查錯誤,但同時可能把公式、門檻值、工具選擇與驗證流程一併暴露。
如果想進一步了解,最直接是先看論文與 CapTraceBench 的設定,再對照自己團隊有沒有公開 trace、審計留痕或第三方驗證需求。項目現階段重點在研究驗證,不是即裝即用型產品,所以較適合安全研究、代理平台、企業內部治理與學術實驗場景。
- 保留 auditability:輸出、工具使用證據、執行順序與 verifier 需要的欄位仍可保留
- 加入 protection:公式、thresholds、implementation details、tool dependencies、private heuristics 會被抽象化或隱去
- 提供 provenance 能力:可選 behavioral watermark hooks,方便分析下游是否重用行為模式
- 配套基準 CapTraceBench:涵蓋 75 個 long-horizon tasks、154 個 curated skills、7 個領域
這項目特別之處在於它不是把整段軌跡直接遮掉,而是把「需要審核的內容」與「可複製的技能細節」拆開處理,再加上 behavioral watermarks 做來源分析。論文數字亦頗具說服力:在代表性的 trace reuse 方法下,REDACT 將 normalized skill transfer (NST) 由原始軌跡的 44.7% 至 67.1%,壓到低於 no-skill baseline;獨立 watermark 偵測的 true detection 達 93.6% 至 100.0%,false alarm rate 最多 1.9%。
相關內容不只包括 RedAct,也包括用來測試外洩風險的 CapTraceBench,以及文中聚焦的 agent traces、procedural skills、behavioral watermarks、black-box trace disclosure 等概念。若你的項目需要公開代理操作紀錄,又不想把核心流程白白送出去,這個研究值得細看;若你要的是完整產品化流程,現時資料仍較偏研究原型。