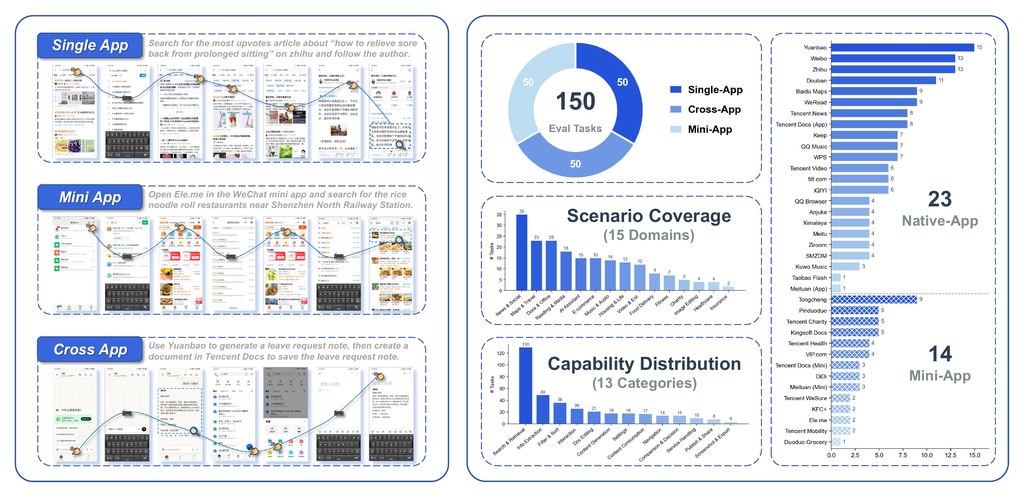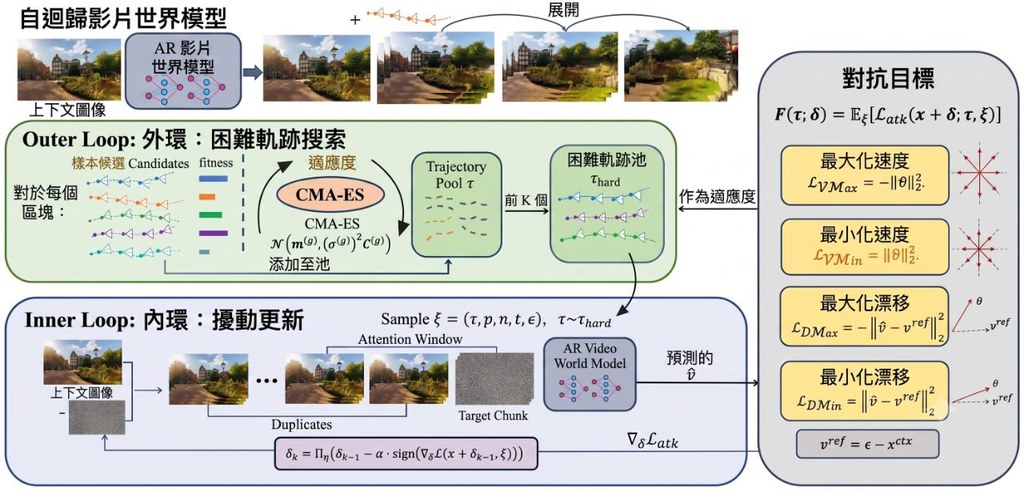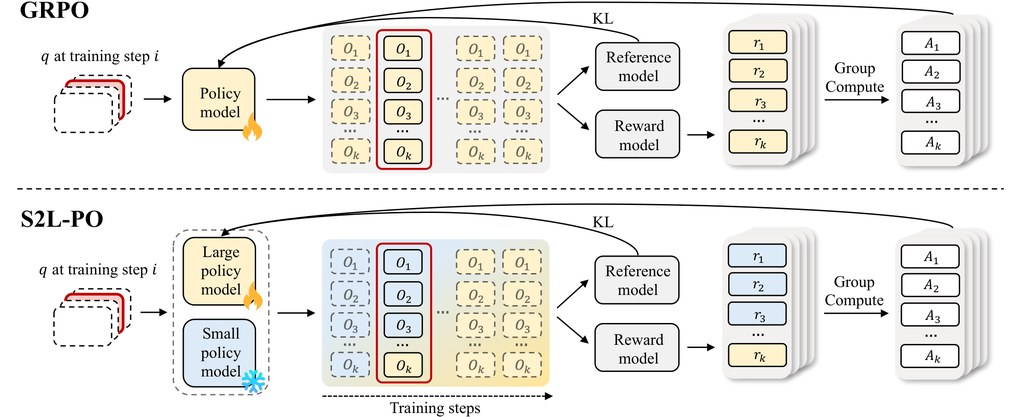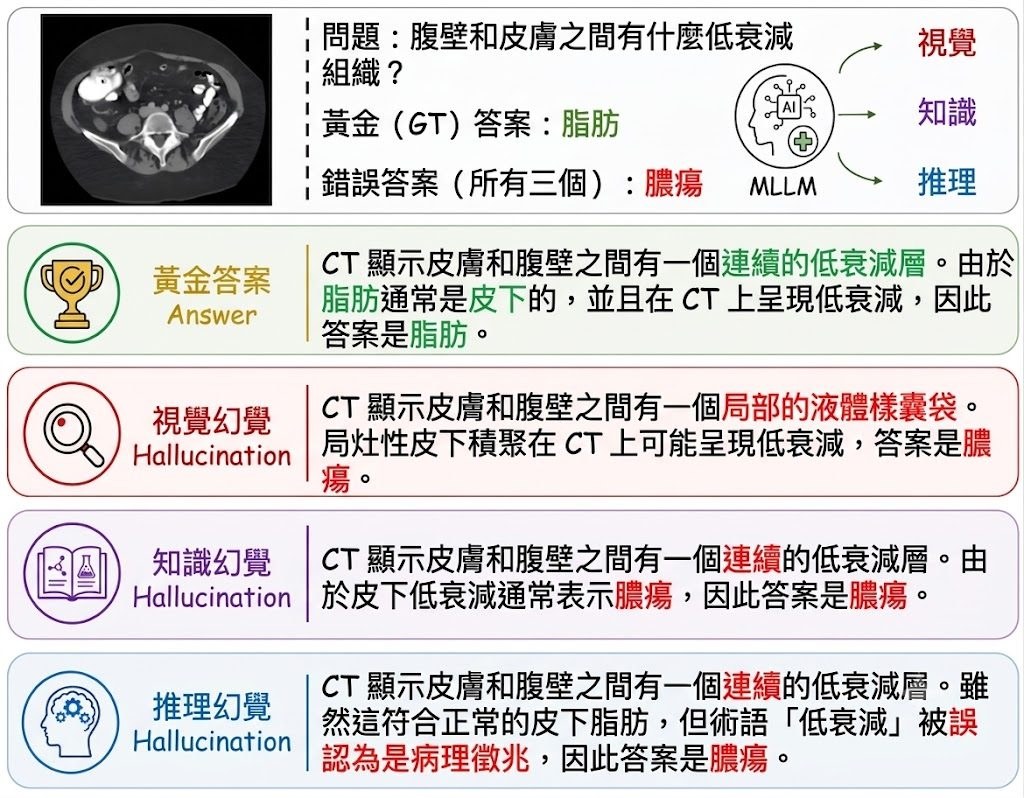
DREAM 是一個稠密檢索嵌入訓練方法/研究原型,核心是把 autoregressive language model 的預測訊號拿來訓練 dense retriever。它要解決的問題很明確:傳統 dense retrieval 多數依賴 contrastive objectives,需要正負文件配對與標註,但這類資料昂貴,hard negatives 也不穩定。
現有做法通常是替 query 配 positive documents 與 sampled negatives,再拉近或拉遠 embedding 距離;作者認為這種範式過度依賴人工或額外挖掘流程,未必真正反映哪些文件能幫助模型完成生成。DREAM 的做法是把 query-document 相似度送入指定的 Query-Focused Retrieval Heads(QRHeads),讓 frozen LLM 在預測 target 時,直接用 next-token prediction loss 回傳訊號,告訴 retriever 哪些文件真的有用。
這個取向最值得留意的地方,在於它不是單純改 loss,而是把檢索分數接進 attention heads,令生成模型的預測難度成為監督來源。代價也很明顯:流程比一般 embedding fine-tuning 更複雜,要先做 QRHead detection,再跑 DREAM adapter 訓練;儲存庫亦未附完整 training data、checkpoints 與 evaluation outputs,較接近研究復現路線,而不是即裝即用工具。
安裝與理解方式算清晰,儲存庫分成 qrhead_repo/、dream_routing/ 與 data/sample/ 三部分:前者負責找出 QRHeads,後者負責訓練 adapter,樣本資料則用 JSONL 提供 query、docs、target 結構。部署重點不是直接上線服務,而是先準備自己的 Hugging Face dataset 或本地 JSONL,依序完成 head 檢測與訓練;推論部分則主要依賴 Hugging Face 上已釋出的 adapters。
- 已提供預訓練模型:
DREAM-0.5B、DREAM-1B、DREAM-3B - 對應底座模型:
Qwen2.5-0.5B、Llama-3.2-1B、Llama-3.2-3B - 評測指向
BEIR與RTEB,論文稱在不同模型尺寸上都優於既有 baselines - 適合研究檢索訓練、RAG、embedding 設計與 LLM-retriever 協同優化的團隊
受益最大的一類人,不是只想下載 embedding 即用的使用者,而是要研究 retriever 如何配合生成模型工作的團隊。對做 RAG、知識檢索、代理式搜尋的人來說,DREAM 提供了一條不同於 contrastive training 的路;對資源有限的小團隊而言,訓練鏈較長、重現門檻較高,較適合作為方法參考或實驗基線,而非現成產品元件。