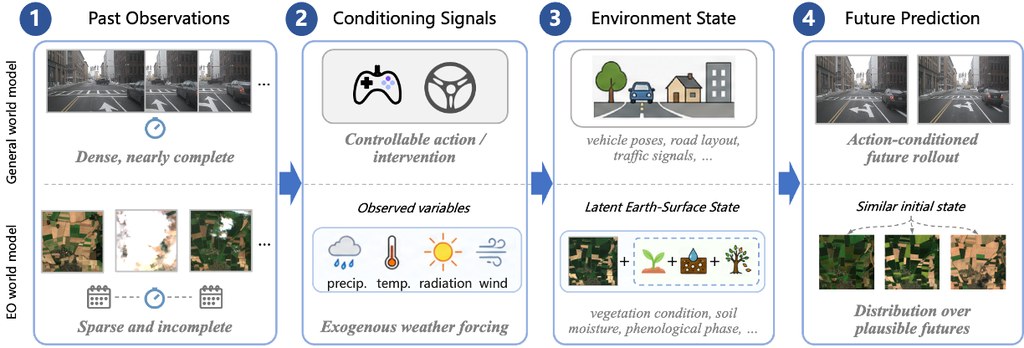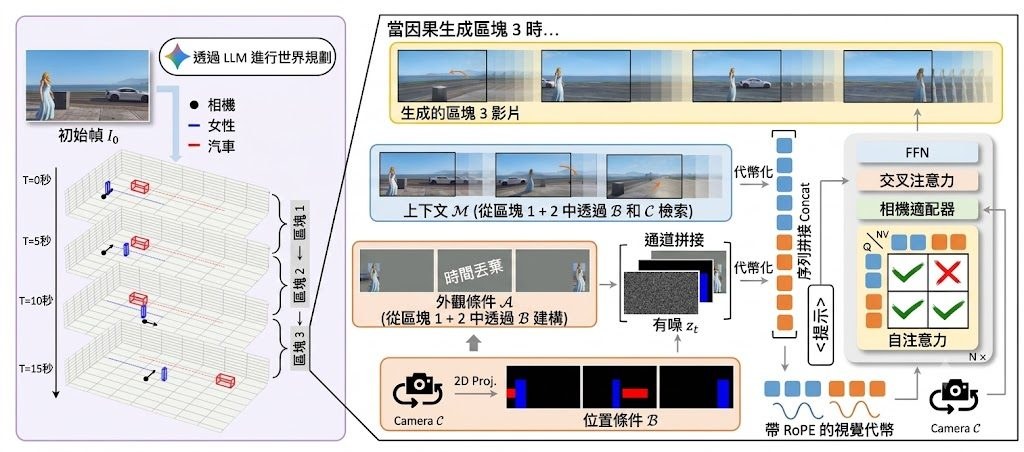
WorldDirector 是一個影片世界模型框架,屬於研究原型兼開源推理項目。它的核心任務,是讓系統在生成長片段影片時,仍能記住動態物件的身份、位置變化與鏡頭運動,減少角色或物件一離開畫面就「變樣」或失去連續性的情況。
它的做法不是直接把所有事情交畀單一生成模型處理,而是先用 Large Language Model(LLM)規劃 3D 物件軌跡與相機路線,再把規劃投影成 2D 控制訊號交畀視覺生成模組。呢種拆分令項目的取向很清晰:先保住語意層面的動作因果,再處理畫面生成,因此比起只靠像素連續性的世界模型,更重視可控性、物件恆常性同長時段一致性。
目前已公開的是完整 inference code 同 WorldDirector-14B 權重,同時亦交代依賴 Torch 2.4.0、FlashAttention,以及 Hugging Face 下載模型的流程。換句話說,現階段較適合已有 GPU 環境、懂得整理 JSON 規劃輸入的人測試;它不是裝完即用的消費級工具,而較接近可重現論文結果的研究型項目。
項目展示的例子集中在人物、車輛、鏡頭切換與長時間事件編排,重點是物件暫時離開視野後再返回,外觀仍能維持穩定。公開資訊提到它支援 persistent dynamic object memory 同 unrestricted viewpoint exploration,但未見提供完整量化基準細節,因此現階段較適合把它理解為一個方向鮮明、控制力強的世界模型方案,而不是已全面驗證的通用產品。
- 類型定位:影片世界模型框架,主打可控生成與長時記憶
- 主要差異:把運動規劃同視覺生成拆開,先處理 3D 語意軌跡
- 較適合情境:研究團隊、影片生成工作流、需要鏡頭與角色一致性的實驗
- 部署理解:需先配置依賴、下載 WorldDirector-14B,並準備符合格式的 JSON 計劃輸入
- 相關模型:WorldDirector-14B;流程中亦依賴 Large Language Model(LLM)參與動作與鏡頭規劃
整體來看,WorldDirector 最有價值的地方,在於它把「世界模擬」由單純畫面續寫,推進到可描述、可規劃、可回放的控制流程。對想研究影片 world model、角色一致性與可操控鏡頭生成的人來說,呢個項目值得留意;對只想快速出片的人,現有門檻仍然偏高。