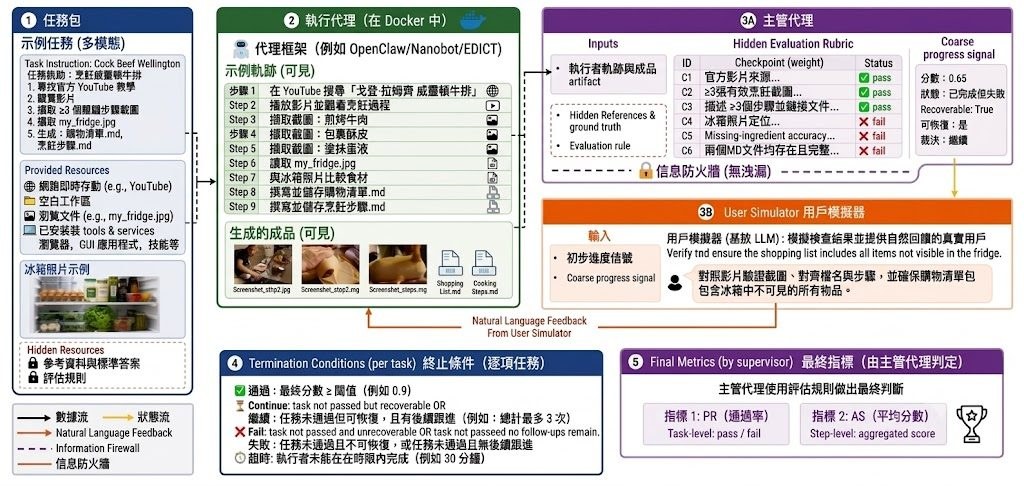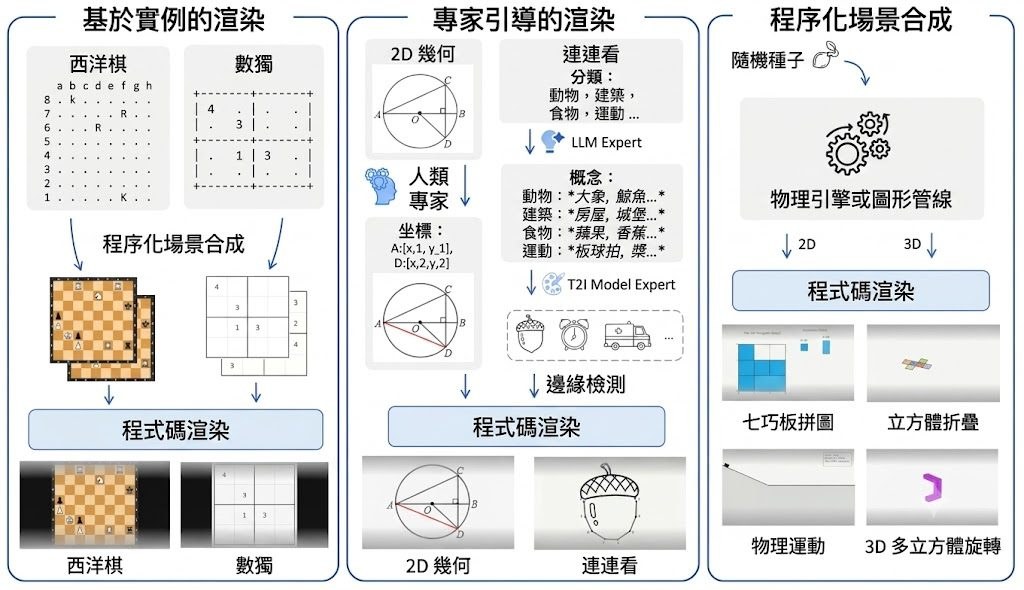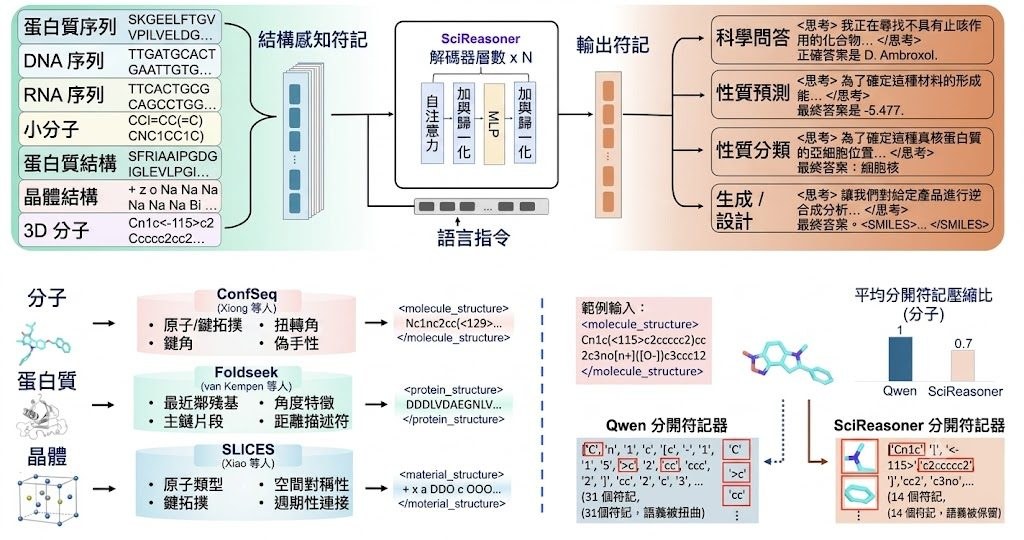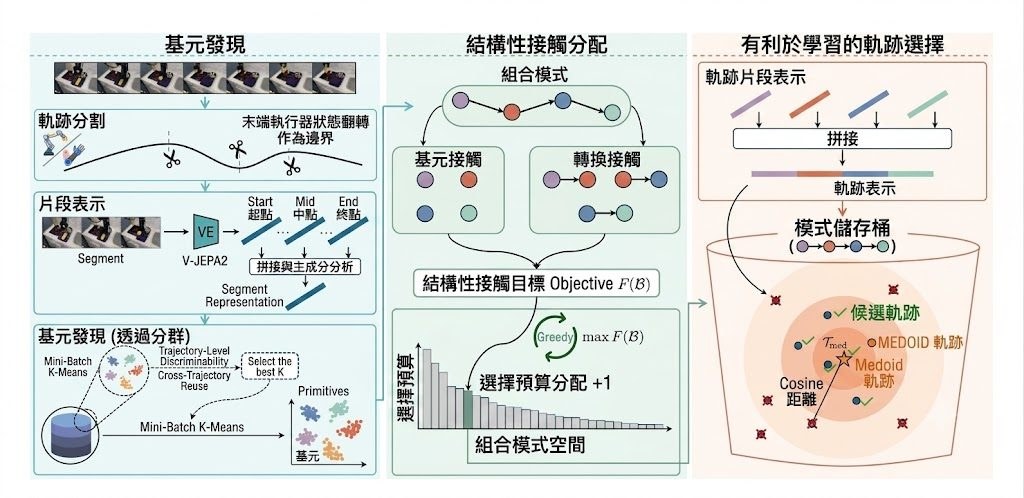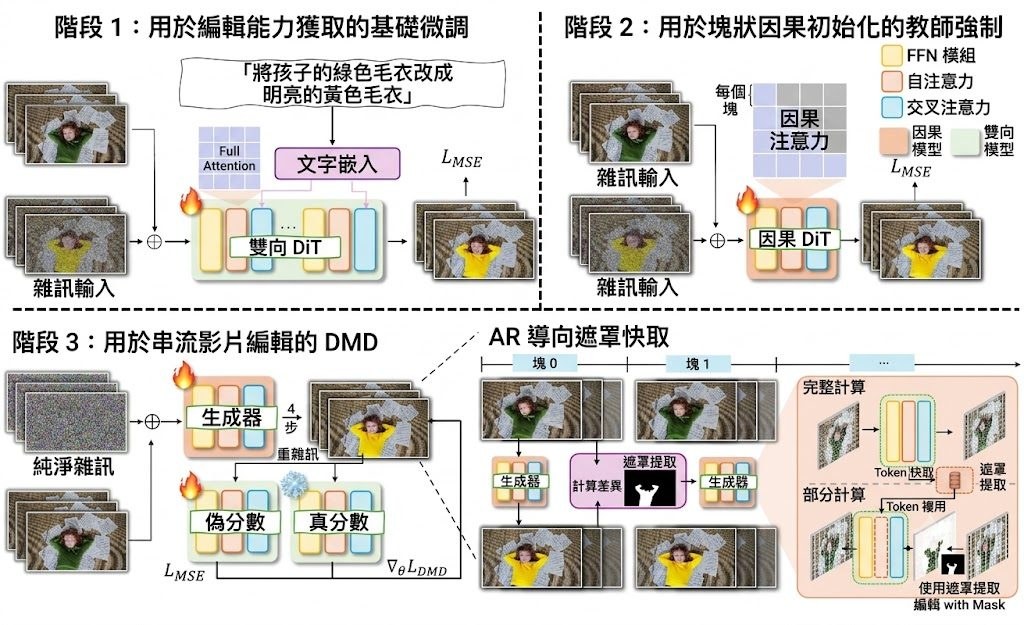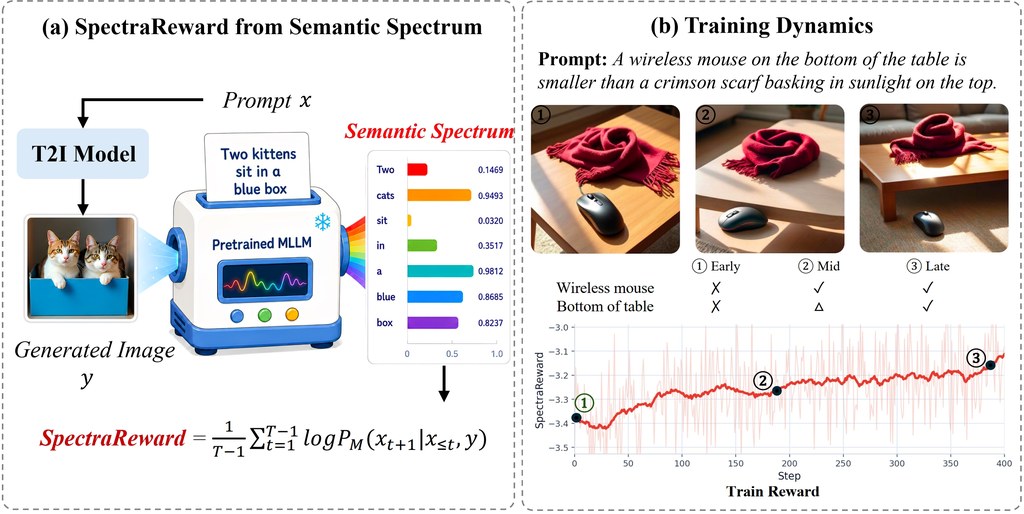
文生圖訓練最麻煩的一環,往往不是生成本身,而是怎樣穩定判斷圖片有冇跟足提示詞。SpectraReward 屬於影像生成 reinforcement learning 的獎勵方法,處理的正是這個問題:它不靠人工偏好標註,也不用再微調 reward model,而是借用預訓練 Multimodal Large Language Models(MLLMs)本身已有的圖文對齊能力,直接替生成結果打分。
核心做法很直觀:先讓 MLLM 看生成出來的圖片,再檢查它能否把原本的 prompt「讀返出嚟」。SpectraReward 用一次 image-conditioned、teacher-forced forward pass,計算 prompt 的平均 log-likelihood,數值越高,代表圖片越能還原文字意圖。相比常見做法要模型直接評分、回答拆解後的驗證問題,這個方法少了額外訓練步驟,也減少了設計評分流程的負擔。
項目亦提出 Self-SpectraReward,對 BAGEL 這類 unified multimodal models(UMMs)尤其有意思。做法是讓同一個模型的 understanding branch,為 generation branch 產生的樣本評分,形成 self-reward。這種安排的重點不在模型愈大愈好,而在 reward 與 policy 是否真正對齊;資料指出,這種內部對齊效果有時可追平,甚至超過更大型的外部 MLLMs。
- 不需要 preference labels,也不需要 reward-model fine-tuning
- 只用一次 MLLM forward pass,就可計出 training-free reward
- 把「圖片能否還原 prompt」變成可量化的獎勵訊號
- Self-SpectraReward 適合 BAGEL 類 unified multimodal models(UMMs)
從結果描述來看,reward 提升時,複雜場景生成質素也同步改善,表示這個訊號不只理論上合理,亦能推動可見的畫面進步。對正在做 text-to-image generation、影像模型強化學習,或想減少外部獎勵模型依賴的讀者來說,SpectraReward 提供了一種更省步驟、但仍保留語義判斷能力的路線。文中提到的模型包括 MLLMs,以及 BAGEL 這類 unified multimodal models。