PhoneBuddy 是一個開放式 phone-use agent 訓練研究項目,也是面向手機操作代理的模型訓練配方。它主要解決的問題,是讓代理不只會看畫面點擊與輸入,還能同時從真實手機執行回饋與可重設、可驗證的模擬環境中持續改進。
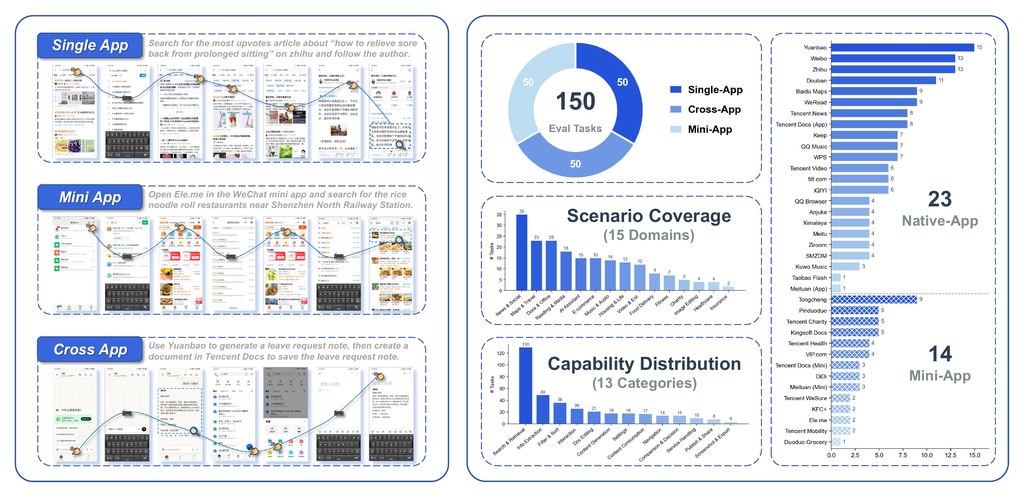
現有 mobile agents 常被當成 GUI controller 來訓練或評測:看螢幕、點擊、輸入、滑動,再重複下一步。PhoneBuddy 指出,單靠真實 App reinforcement learning(RL)雖然更貼近真機,但成本高、難重設、驗證麻煩;只靠 PhoneWorld 風格的 mock-app RL 又較易擴展,卻未必完全反映真實手機情境,所以它採用 real-app RL 加 mock-app RL 的混合路線。
這個取向的重點,不是單純把資料加多,而是把兩種訊號分工:真實執行提供 realism,模擬環境提供 resettable 與 verifier-backed tasks。根據公開頁面,PhoneBuddy-4B 在 Real+Mock RL 後,AndroidWorld 成功率達 83.2%,比只做 real-app RL 平均高 5.0;不過 cross-app 任務只有 18.0,反映跨 App 長流程仍是明顯短板。
現階段較適合把它理解成研究原型加公開模型,而不是完整可即裝即用產品。公開資訊顯示已有 Hugging Face 模型,包括 PhoneBuddy-4B、PhoneBuddy-4B-RealApp 與 PhoneBuddy-0.8B;但 code release、evaluation documentation 仍在補,dataset 亦未公開,所以目前較合理的測試方式,是先比較不同 checkpoint 的能力定位,再配合 PhoneWorld、PhoneHarness、PhonePrivacy、PhoneSafety 這條研究線一併理解。
- 核心差異:把 real-app RL 的真實性,與 mock-app RL 的可驗證擴展性結合
- 已公開模型:PhoneBuddy-4B、PhoneBuddy-4B-RealApp、PhoneBuddy-0.8B
- 公開成績:AndroidWorld 83.2%,平均比 real-app RL only 高 5.0
- 主要限制:cross-app 表現偏低,資料集未公開,程式與評測文件仍未齊備
- 較適合人群:研究 Computer-use agents(CUAs)/手機代理、做 agent training、benchmark 或安全與私隱分析的團隊
想了解「手機代理怎樣訓練得更像真機、又不至於每次都要真人手動重置環境」,PhoneBuddy 的判斷相當清晰:真實世界負責可信度,模擬世界負責規模。它未必已經提供完整部署流程,但作為 open phone-use agents 的訓練方向,取捨、限制和下一步研究空間都表達得很明確。
GitHub: https://github.com/PhoneBuddyAI/phonebuddy