想將觸覺資料接入小型多模態模型,最麻煩的地方往往不是接唔接到,而是模型一邊學「摸到乜」,一邊把原本「睇到乜」的能力搞亂。SPLASH屬於模型訓練框架,針對的正是 MLLMs 在加入 tactile perception 後容易出現的 catastrophic forgetting,目標是在保住 vision-language 能力之下完成 visuo-tactile 對齊。
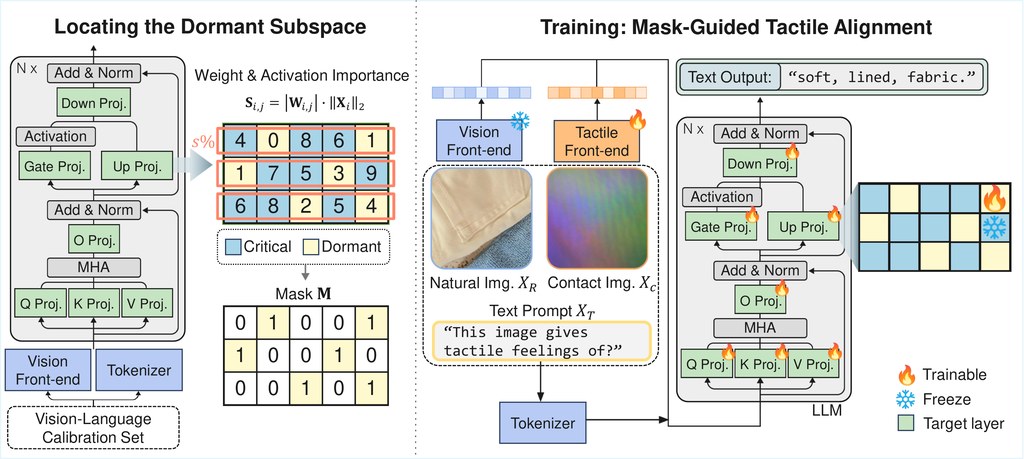
它的取向幾清楚:唔係全面重訓,也唔係隨便加一條 tactile branch 就算,而是先在 LLM backbone 入面找出較「沉睡」的參數空間,再把觸覺學習限制在呢部分。項目提到它用 weight 與 activation importance scoring 生成 dormant masks,之後做 mask-guided sparse training;好處是唔使大幅動到關鍵視覺語言參數,代價則是整個流程仍然偏研究型,部署前要先備好資料集、分割資料,同時需要 CUDA 12.0 以上與至少兩張 GPU 做分散式訓練。
現有版本主要有兩個模型變體:SPLASH-1B 以 InternVL2.5-1B 為 base MLLM,SPLASH-3B 則建基於 Qwen2.5-VL-3B,兩者都配合 ViT-Tiny + MLP adapter 作 tactile frontend。資料部分亦唔算輕量,除了 LLaVA-CC3M-Pretrain-595K 與 CC3M 用來生成 mask,仲要配合 Touch-Vision-Language-Dataset、TacQuad 等項目做訓練與 OOD 評估,所以它比較適合做多模態研究、機械感知、或想驗證觸覺—視覺聯合推理的團隊。

- 重點不在新增多少參數,而在把觸覺更新隔離到 dormant subspace
- 基底模型包括 InternVL2.5-1B 與 Qwen2.5-VL-3B
- 觸覺前端採用 ViT-Tiny + MLP adapter
- 評估覆蓋 SSVTP、TVL、TacQuad,並強調保留原有通用能力
以公開資訊判斷,SPLASH最值得留意的不是單一 benchmark 分數,而是它明確押注「non-destructive modality expansion」:讓模型多學一種感官,而唔需要用視覺能力做交換。對打算在緊湊參數預算下擴展 MLLMs 感知模態的研究項目而言,這個方向比單純追高表現更有參考價值。