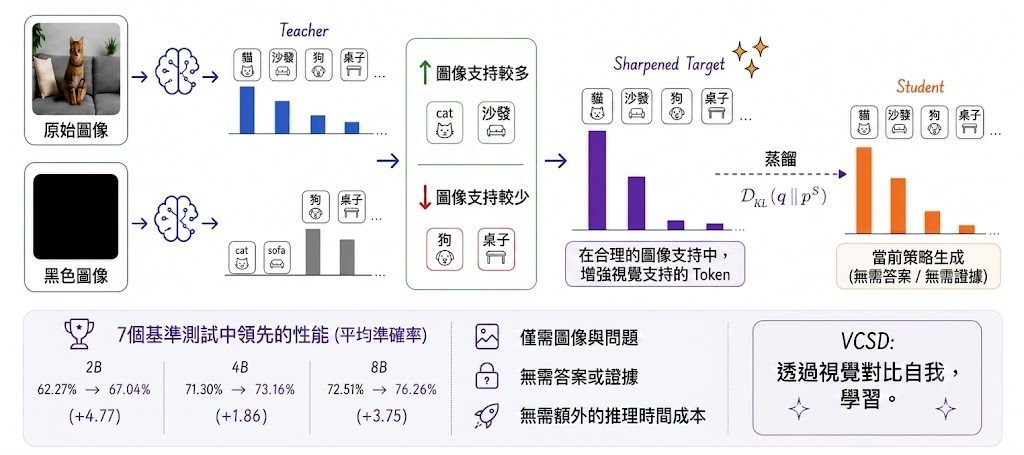
當團隊已經用 AI 加快寫 code,真正卡住進度的往往變成 code review。呢次公開嘅 Open Code Review,重點不只是「AI 幫你睇程式」,而係想處理大型變更集難審、人工 review 跟唔上,以及商業工具長期按席位收費呢幾個現實問題;內容亦提到它來自阿里巴巴內部使用背景,定位係開源嘅 AI code review 項目。
現有資料將焦點放喺幾個差異:它採用結合 deterministic pipelines 同 LLM agent 嘅混合架構,目的係補足一般通用 agent 喺大型 changeset 上容易漏看脈絡、穩定性不足嘅情況;同時內建 ruleset,並且強調可以直接整合到 Claude Code。資料亦提到 Apache 2.0 授權、可免費使用,同埋私有化操作係其中一個賣點。
重點可先整理成幾項:
– Open Code Review 屬於開源 AI code review 項目,面向開發團隊審查程式變更流程
– 核心賣點係免費、可私有化,以及針對大規模 code review 場景設計
– 架構結合 deterministic pipelines 與 LLM agent,用意係提升大型變更審查嘅完整度與穩定性
– 內容提到它曾服務大量阿里巴巴開發者,並找出大量缺陷,但未見更完整技術細節與驗證方法
– 可安裝到 Claude Code 之中使用,不過現有資料未提供完整步驟
以讀者角度睇,最受用嘅會係已經開始用 AI 寫 code、但 review 成本持續上升嘅團隊,尤其關心內部程式碼唔想外流,或者想將審查規則固定落流程入面嘅情境。呢類工具值唔值得跟進,關鍵唔只在於它是否「有 AI」,而係能否喺私有環境中穩定處理大變更,並且減少人工逐行追查嘅負擔。
同一時間,原始資料有限。現時只有影片標題、描述同極少量頁面文字,未提供完整安裝流程、下載連結、規則內容、性能數字來源,亦未交代它點樣接入 Claude Code 或本地模型,因此文章只能按已知資訊整理方向,未適合延伸成操作教學。