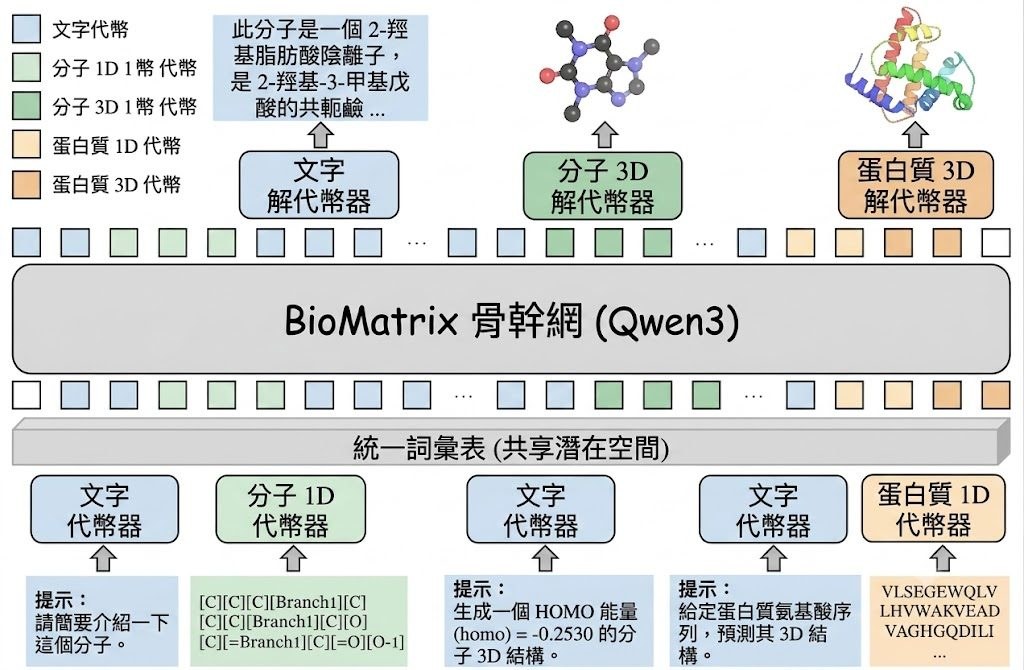
BioMatrix 是一個多模態 foundation model,建立在單一 decoder-only 架構之上。它要解決的問題,是把 molecules、proteins、1D sequences、3D structures 與自然語言放進同一套生成流程,令模型不只可讀取不同資料,也可用同一個 next-token prediction 目標處理與輸出它們。
現有 biological foundation models 通常分成兩類:一類可在共享目標下融合多模態,但多數只集中單一 entity type;另一類雖然覆蓋 molecules 與 proteins,卻常常欠缺顯式 structural modeling,或者依賴 adapter-based designs、external encoders、projection adapters 與 modality-specific output heads。BioMatrix 的取向很鮮明:直接把 SMILES、SELFIES、分子 3D、蛋白質序列、蛋白質 3D 同自然語言映射到 shared discrete token space,將「可讀」與「可生成」統一。
技術上,這個項目最值得留意的是 unified tokenization scheme。分子 3D 用改良版 MolStructTok,蛋白質 3D 用 GCP-VQVAE,並以 description-based embedding initialization 把新增 token 先對齊到 pretrained Qwen3 embedding space,再做 continual pretraining;這種做法比起後加模態接頭更完整,但訓練成本亦明顯更高,官方資料提到曾用 64 張 NVIDIA H100 GPUs 配合 LLaMA-Factory 訓練。
從 GitHub 與 Hugging Face 現有資訊看,這個項目較適合當作模型下載與研究評測基線使用,目前可找到 BioMatrix-1.7B-Base、BioMatrix-4B-Base、1.7B-SFT、4B-SFT 等版本。若你想測試,較合理的理解方式是先用已發佈模型做推理或任務比較,再按需要研究其 tokenizer,例如 MolStructTok 與 GCP-VQVAE;完整重訓對一般團隊門檻很高。
- 模型定位:多模態 biological foundation model,不是單一分子模型或單一蛋白質模型
- 核心差異:把 sequences、structures、language 放入同一 shared discrete vocabulary,而非靠外掛式模態模組拼接
- 相關模型:Qwen3 1.7B、Qwen3 4B、BioMatrix-1.7B-Base、BioMatrix-4B-Base、BioMatrix-1.7B-SFT、BioMatrix-4B-SFT
- 數據與訓練:涵蓋 text、PubChem、MolTextNet、UniRef50、RCSB PDB、UniProt/Swiss-Prot、AFDB 及 cross-entity interleaved data
- 表現指標:論文稱 instruction tuning 後涵蓋 80 個 tasks、6 個類別,當中 77 個 tasks 達到 state-of-the-art 或具競爭力
這個項目最受惠的會是做 drug discovery、protein engineering、生物資訊研究,或者想把文字問答、分子表示與結構生成放進同一工作流的團隊。它的野心很大,優勢是統一表示與任務泛化,限制則是部署與訓練門檻高,而且論文聲稱的廣泛表現仍要看你手上的任務是否屬於那 80 個測試範圍。
GitHub: https://github.com/QizhiPei/BioMatrix