PilotTTS 是高德地圖(Amap)團隊在 GitHub 上開源的文字轉語音(text-to-speech, TTS)項目,主打以 LLM-based 架構配合嚴謹的資料工程,用較少資源做出具競爭力的合成品質。對想研究語音生成、卻沒有百萬小時資料和龐大算力的團隊來說,這是一個值得關注的選擇。
這個項目要解決的問題很直接:現今最頂尖的 TTS 系統往往依賴數百萬小時的私有資料和複雜的多階段架構,進入門檻極高。PilotTTS 反其道而行,僅以 20 萬小時、以全開源工具處理的資料集進行訓練,並釋出從品質評估、標註到過濾的完整資料管線(data pipeline),讓其他研究者能重現並改良。
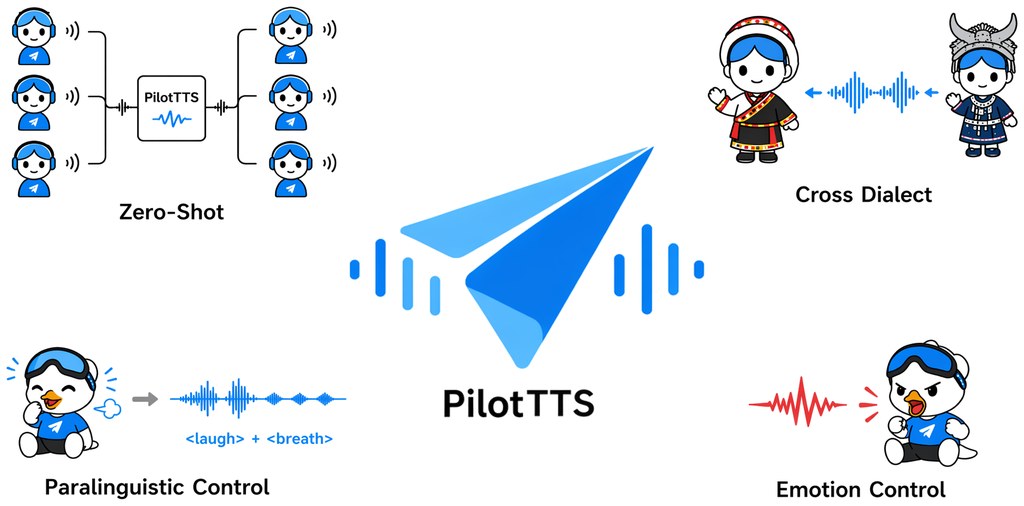
在功能面上,項目涵蓋四個面向:零樣本聲音複製(zero-shot voice cloning)、11 種情緒合成、4 種副語音效果(如笑聲、呼吸、咳嗽、哭聲),以及 14 種中文方言的跨方言合成。模型方面,權重分為 pilot_tts.pt(基礎模型)與 pilot_tts_instruct.pt(指令控制版本),可從 HuggingFace 或 ModelScope 下載,配合 w2v-bert-2.0 等開源特徵提取器即可運作。
評估結果方面,團隊在 Seed-TTS Eval 基準上報出了亮眼數字:英文測試集 WER 1.50%、中文 CER 0.87%,兩組測試的說話人相似度(speaker similarity)分別達到 0.862 與 0.815,勝過多個以更大資料集訓練的系統。模型採用 Q-Former-based conditioning,透過跨樣本配對訓練把說話人身份與語氣風格解耦,這是它在精簡架構下仍能保持高表現的關鍵設計之一。
對一般讀者而言,這個項目較適合從事語音合成、LLM 多模態應用或中文方言研究的開發者與學生;對想打造有聲內容、配音工具或無障礙語音介面的產品團隊,它也提供了可直接整合的開源權重與推理流程。
重點摘要
- 極簡架構:LLM-based 自迴歸模型,以 20 萬小時開源資料處理後的訓練集達到頂尖基準成績。
- 完整資料管線:品質評估、標註、過濾全部使用公開工具,可重現且成本較低。
- 多維度控制:支援 11 種情緒、4 種副語音、14 種中文方言的跨方言合成。
- 頂尖指標:Seed-TTS Eval 取得最高說話人相似度,中文 CER 僅 0.87%。
- 完整開源:模型權重、處理管線與程式碼均於 GitHub、HuggingFace、ModelScope 釋出。