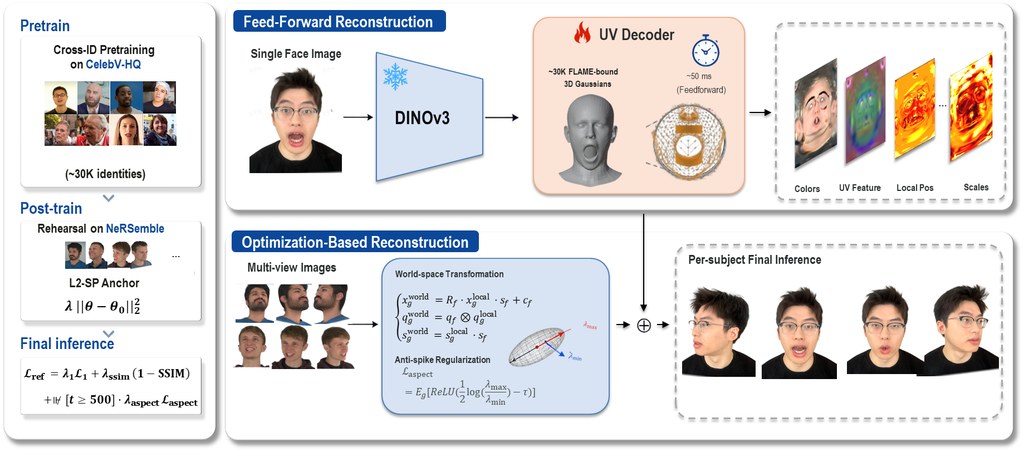
SpatialAvatar-0 針對的是 4D head avatar 重建:只靠一張或少量 source portraits,就生成可配合時間變化的頭像表示,適合 telepresence、AR/VR 同 digital-human interaction。它採用 FLAME-mesh-bound Gaussian 表示,核心是把 feed-forward generator 同 per-subject refinement 放入同一套結構,減少以往兩類方法各自為政的問題。
常見做法通常分成兩路:一類是可直接預測的模型,速度快,但容易受訓練數據領域限制;另一類是按單一人物慢慢微調,質素高但迭代很長,還會因 adaptive densification 打亂原本 Gaussian 佈局。SpatialAvatar-0 的差異,在於加入 parameter-free K-source mean-pool,支援可變數量輸入,並用 monocular-temporal 到 multi-view-spatial 的兩階段訓練,嘗試減少 identity-prior collapse。
微調部分也有明顯取向:它不是走 300K 至 600K iterations 的長流程,而是保留佈局的 10K-iter refinement loop,凍結 FLAME 綁定與 Gaussian 數量,再以 three-component anti-spike regularization 取代 densification。對想保留上游表示、又想做人物級細修的工作流,這種設計會較容易接軌。
已公開資料顯示,它在 VFHQ、HDTF 的 cross-domain zero-shot 測試中,PSNR 比 GAGAvatar 高 1.5 dB,而且模型未有在這兩個測試領域訓練;在 SplattingAvatar monocular benchmark,亦全面領先已報告指標,較 300K-iter 的 GeoAvatar 高 1.3 dB PSNR,同時把單人物微調流程縮短至最多 60 倍。數字反映它著重的是泛化能力與重建效率的平衡,但具體效果仍要視輸入人像質素與場景條件而定。
- 支援一張或多張人像輸入,重建高質 4D 頭像
- 統一 feed-forward generator 與 per-subject refinement 的表示方式
- 10K-iter 微調流程,比常見長迭代方法短得多
- 在 VFHQ、HDTF、SplattingAvatar 基準上有明確成績提升
頁面暫未提供 Code 與 🤗 Model 入口。對 3D Gaussian Splatting(3DGS)、數字人、AR/VR 內容製作有興趣的讀者,可以先從示範效果理解它的輸出風格,再留意它如何處理少樣本輸入與跨資料域表現。文中引用模型包括 GAGAvatar、GeoAvatar。