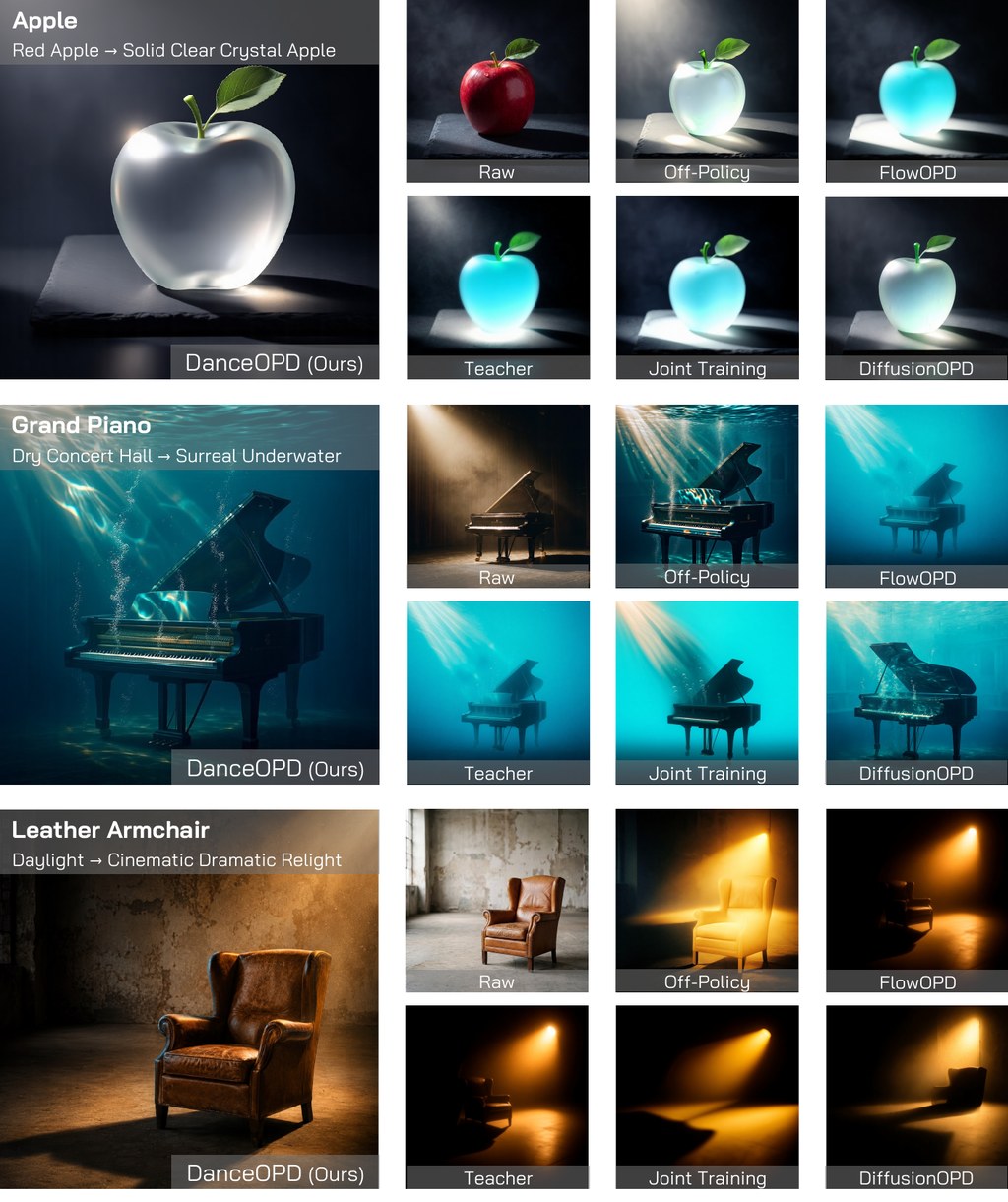
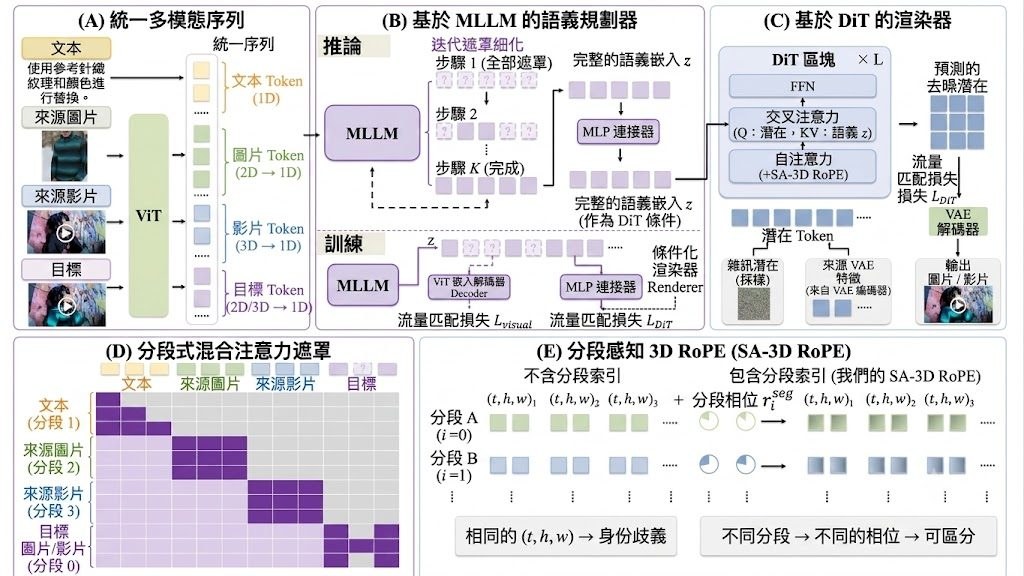
人類操作數據廉價、豐富且多樣化,使其成為擴展機器人學習規範最有前景的資源之一。然而,將人類技能遷移到機器人仍然困難重重:以往的大多數工作都將人類視為另一種雙手6自由度(6DoF)的具身模型,這存在兩個問題:手部姿態估計存在噪聲,並且人類手指的接觸模式與並聯機械臂的接觸模式存在根本差異,導致手腕旋轉與機械臂操作在語義上不一致。我們認為,從人類資料中學習包含旋轉的動作訊號並非最優方案,因此提出了一種 橋接動作表示:在初始頭部-攝影機座標系內的相對手腕平移,這是一個人類和機器人共享的動作空間。
如何把人類操作資料轉移到使用 parallel grippers 的雙手機械人,重點方法是用「relative wrist translation within the initial head-camera frame」作為 bridging action representation。
作者認為把人類直接當成另一種 bi-manual 6DoF embodiment 並不理想,因為手部姿態估計本身有噪聲,而且人手手指接觸模式與 parallel gripper 有本質差異。與其硬學包含旋轉的動作訊號,這項工作改為只保留更容易跨人類與機械人共享的平移資訊,減少 embodiment mismatch。
作者建立了一個 π0-like vision-language-action model,配合 interleaved action tokens 與 attention masking,處理不同 embodiment 可能缺少某些動作成分的問題。這種設計的意義,在於模型不需要假設人與機械人擁有完全相同的控制維度,較適合跨載體技能遷移。
- 以 wrist translation 取代完整 6DoF human actions,降低人手到夾爪的表示落差
- 採用 vision-language-action 架構,並加入 interleaved action tokens 與 attention masking
- 在 novel bi-manual manipulation tasks 上,較 noisy 6DoF human actions 有更有效的知識轉移
- 效果會隨 human data 數量增加而提升,說明方法具備一定擴展性
這項內容較接近方法論與表示學習分析,而不是部署指南。頁面沒有列出推論框架、硬體需求、v2 檔案更新、chat template 或 MTP draft speculation 等資訊;能確定的是,它針對 Robotic 技能轉移提出一種更貼近夾爪機械人控制需求的動作抽象,適合關注 imitation learning、cross-embodiment transfer 與雙手操作研究的人閱讀。