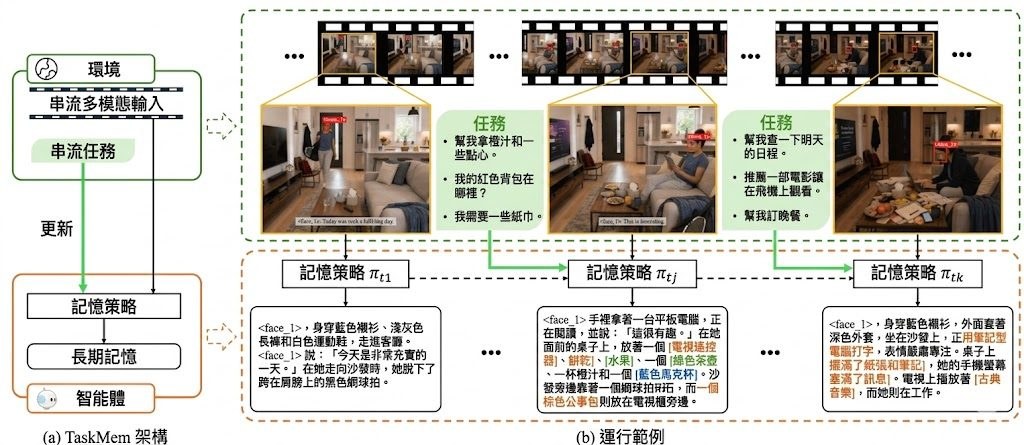
多模態智能體在持續觀察環境時,會接收海量且不斷累積的視覺與語言資訊。若把所有內容都存進長期記憶,既不實際也容易雜訊過多。Task-Focused Memorization for Multimodal Agents 這份研究,把焦點放在一個根本問題:智能體到底應該記住什麼?
來自 ByteDance Seed 與復旦大學的作者群提出名為 TaskMem(Task-focused Memorization Policy Learning) 的框架,把記憶生成視為一項可學習的策略。系統採用兩階段訓練:第一階段先學習怎樣記得準確,第二階段則在部署後,根據近期遇到的任務調整一個 adapter,使基礎多模態大型語言模型(MLLM)偏向記錄與任務相關的內容。整個過程以強化學習驅動,獎勵訊號來自真實任務的表現。
為了評估記憶品質,研究團隊將 VideoMME、EgoLife 與 EgoTempo 改造成串流基準,模擬智能體邊觀察邊回答的場景,且回答時只能依賴記憶,不能翻看原始影片。基於 Qwen3-VL-30B-A3B,TaskMem 在三個基準的 VQA 準確率分別提升 6.3%、7.0% 與 5.3%,並在多項指標上超越 Gemini-2.5-Pro、GPT-5.2 等大型模型。
這項工作對從事多模態智能體、機器人記錄系統或長期對話助手開發的研究者特別有參考價值,因為它把「該記什麼」變成可優化的決策,而非寫死規則。對於關注世界模型與持續學習(continual learning)的團隊,TaskMem 亦提供了一個結合任務回饋與記憶策略的可行路徑。
重點摘要:
- 核心問題:多模態智能體面對資訊洪流,需要學會選擇性記憶。
- 方法:以強化學習訓練記憶策略,分為基礎保真度與任務相關性兩階段。
- 評估方式:將三個影片基準改造成串流設定,僅以記憶回答問題。
- 成效:在 VideoMME、EgoLife、EgoTempo 上 VQA 準確率提升 5.3% 至 7.0%。
- 適用對象:研究多模態智能體、機器人記憶與持續學習的開發者與學者。