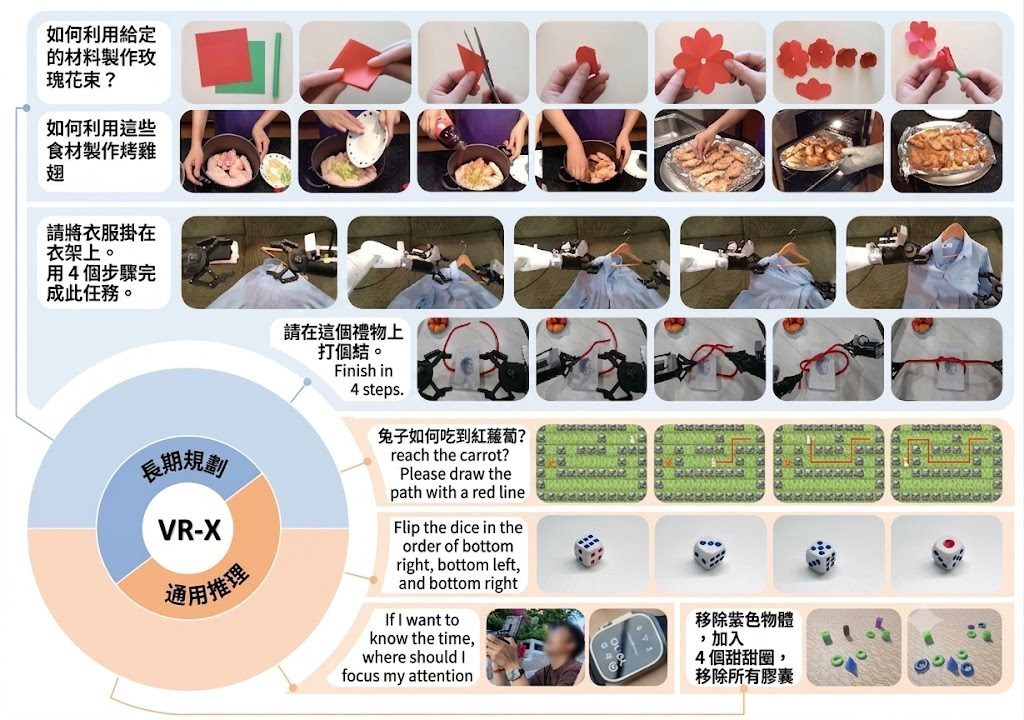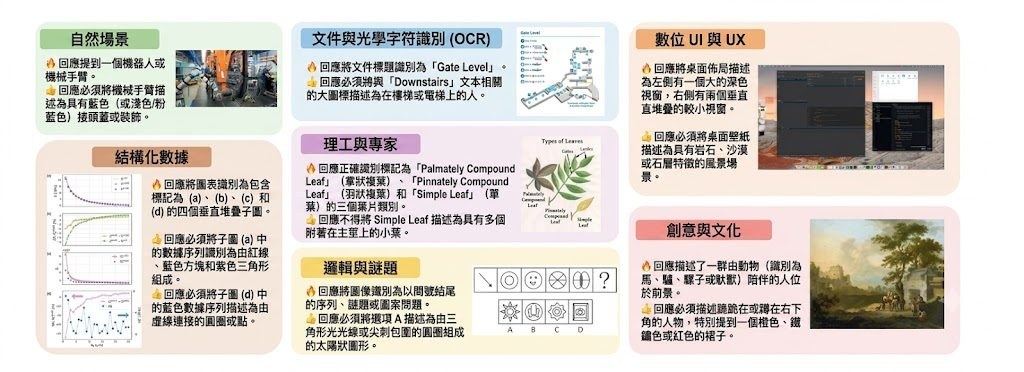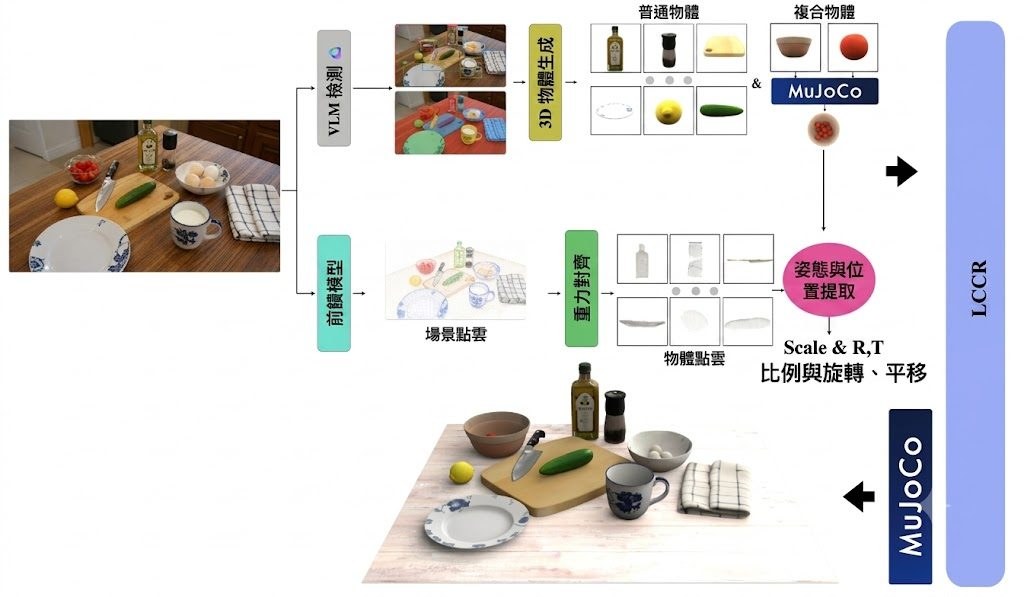
機械臂要學會喺凌亂桌面執放物件,卡位通常唔在控制器,而在訓練資料太乾淨、太想像化。TableVerse 屬於Dataset 數據集加上資料生成流程,重點不是再用文字幻想場景,而是用 Real2Sim 從網上真實圖片重建可放進模擬器的桌面配置,直接處理泛化操作最缺的場景真實感。
現有做法常見兩條路:text-to-layout hallucination,或者較簡化的 procedural generation。作者批評前者容易做出物理上唔合理的擺位,後者又捉唔到人類日常環境常見的密集雜物;因此 TableVerse 改成 deterministic reconstruction,從非結構化的 in-the-wild image data 還原具備 metric scales、authentic topologies 同 verified mechanical stability 的場景,取向明顯偏向可落地訓練,而唔係只追求合成速度。
項目現時最重要的成果是 TableVerse-100K,公開了 100,000 個 physically consistent 的桌面環境,並配對 interactive manipulation trajectories。網站資料顯示,它還接上自動化 task-conditioned trajectory generation,先由 MLLM 根據場景視角提出 object-to-target 配對,再生成 collision-free pick-and-place demonstrations,令數據不只得靜態場景,亦包含可直接餵給操作策略學習的示範。
- 以真實圖片重建桌面,而非只靠生成式佈局
- 提供 100K 場景與 pick-and-place 軌跡,規模夠大
- 強調物理一致性、機械穩定性與模擬可用性
- 適合做 generalizable manipulation 與桌面操作研究
部署角度上,這個 GitHub 儲存庫目前更接近論文與資料入口,主要連到 arXiv、HuggingFace dataset 同項目網站,未見完整訓練或評測程式公開。換句話說,研究團隊現階段較可能把它理解為高品質資料來源與方法參考,而不是即裝即跑的機械臂框架;對做 robotic manipulation、模擬訓練數據建構,或者研究 Real2Sim 流程的人,參考價值很高。