由清華大學、上海 AI 實驗室及北京航空航天大學共同推出的 OVO-S-Bench,是一套專門測試多模態大型語言模型 (Multimodal Large Language Models, MLLMs) 在連續影片中空間理解能力的基準。它針對機械人、AR 眼鏡和自動駕駛等需要「邊看邊想」的真實場景,要求模型根據問題時間點之前看到的畫面片段,推理出地點與佈局的變化,而非讀取整段影片。
題目來源相當多元,涵蓋室內導覽、第一視角活動、戶外場景、駕駛影片及帶有 3D 註解的環境,共 348 段影片。12 位具備 3D 視覺背景的標註員耗時約 804 小時撰寫及反覆核對每條題目,並透過「文字探針」和盲測覆核機制,剔除可憑題幹文字或常識直接答對的題目,確保難度真正來自空間理解。
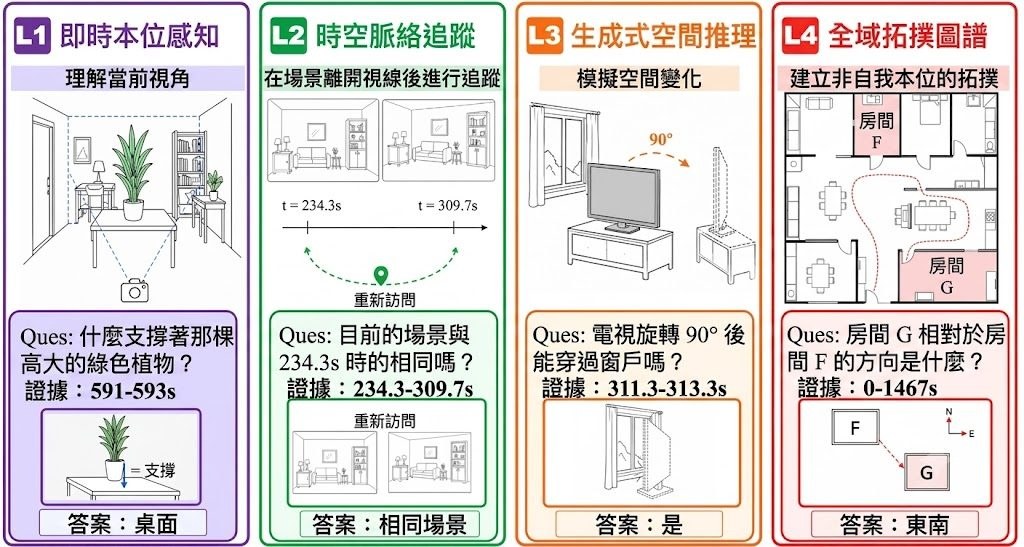
題目分為四個難度層級,由當下畫面的瞬時感知 (Instantaneous Egocentric Perception)、追蹤離開視野的空間脈絡 (Spatiotemporal Context Tracking)、推測空間變化的生成式推理 (Generative Spatial Reasoning),到建構全局拓樸地圖 (Global Topological Mapping)。在 38 個開源及商用模型的評估中,即使是表現最佳的 Gemini-3.1-Pro,分數仍比人類專家低 27 分 (59.2 比 86.6),全局拓樸層級是最大的樽頸。
更值得留意的是,部分聲稱針對串流或空間任務微調的模型,表現反而不如其底層基座模型;而無根據的思維鏈 (chain-of-thought) 推理,往往會放大空間錯誤。這套基準為下一代串流空間模型提供了清晰且嚴謹的試金石。
重點摘要:
- 涵蓋 1,680 條人工撰寫題目及 348 段影片,總標註工時約 804 小時
- 設有問題時間點及證據區間,評估時模型只看到查詢前的影片片段
- 分為四個遞進難度層級,由瞬時感知到全局拓樸建圖
- 38 款 MLLM 中,Gemini-3.1-Pro 取得 59.2 分,人類專家為 86.6 分
- 串流及空間微調模型表現可能反遜於原底座模型