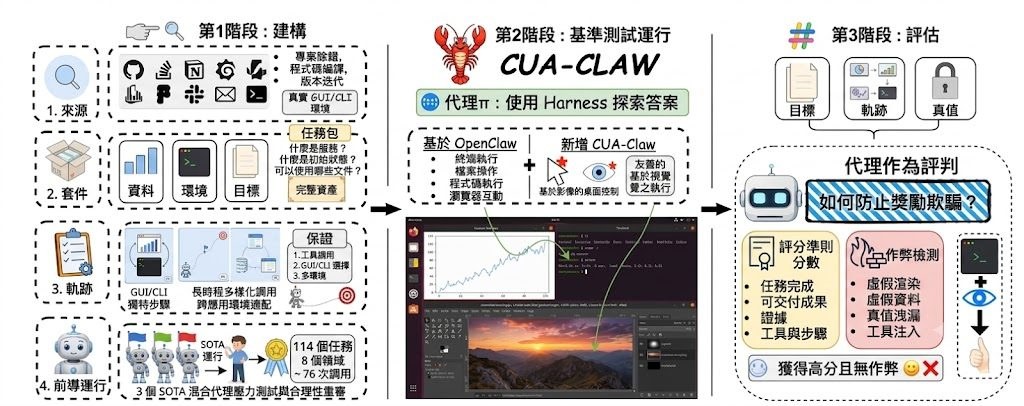
WeaveBench 是一個 benchmark 基準項目,聚焦測試 Computer-use agents(CUAs)在真實桌面環境中,能否把 GUI 點擊、shell 指令與程式碼編修串成同一條工作流程。它處理的不是單一步驟準確率,而是長流程、多介面協作這類更接近日常工作的問題。
這個項目的判分方式比常見的「有沒有生成某個檔案」嚴格得多。它使用 trajectory-aware Agent-as-Judge,會閱讀 chat trace、交付物,並按條款提供證據;論文亦指出,只看最終結果會高估代理表現,這點對研究 CUAs 的人很有參考價值。
如果想先了解它怎樣運作,可以先看離線 demo,直接觀察 score.json、judge model 回應和逐項證據,再決定是否下載完整資料集與 qcow2 執行環境。完整流程需要 Linux、KVM、Docker 及相當多記憶體與磁碟空間,較適合研究團隊、模型評測人員,或正在建構代理系統的工程師。
- 114 個長流程任務,涵蓋 8 個工作領域
- 每個任務都要求 GUI 與 CLI/code 交替操作
- 最佳公開結果為 41.2% PassRate,顯示難度仍然很高
- 提供 OSWorld hybrid-scoring experiment,可對照不同評分與執行框架
- 資料集、runtime 與 qcow2 已放在 🤗 wanlilll/WeaveBench
相關模型與組合方面,公開結果包括 Claude Opus 4.7 + Claude Code、Claude Opus 4.7 + OpenClaw、GPT-5.5 + Codex CLI、GPT-5.5 + OpenClaw、GPT-5.4 + OpenClaw,以及 Gemini 3.1 Pro + OpenClaw。若你關心代理是否真的懂得跨介面完成工作,而不是只會在單一測試集刷分,這個項目很有研究價值。