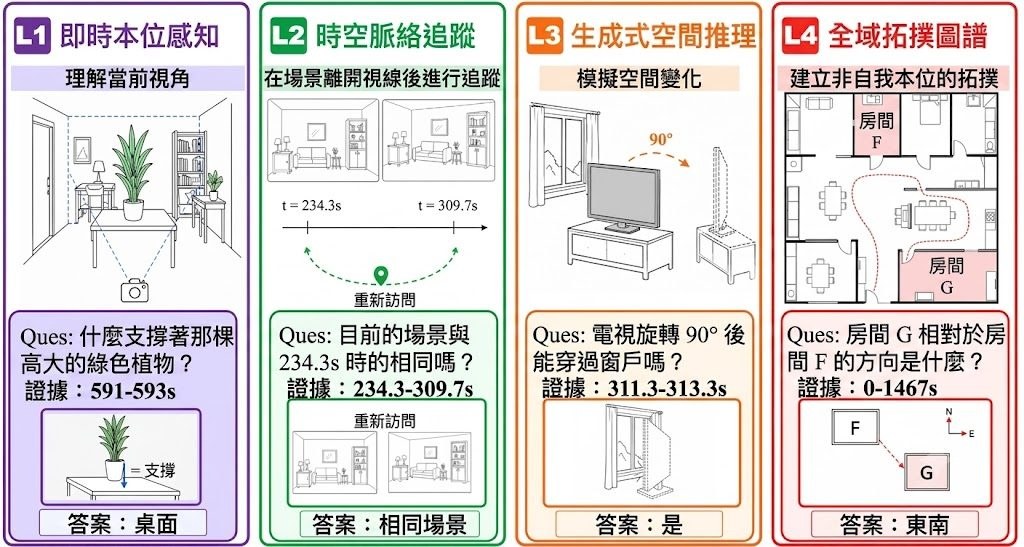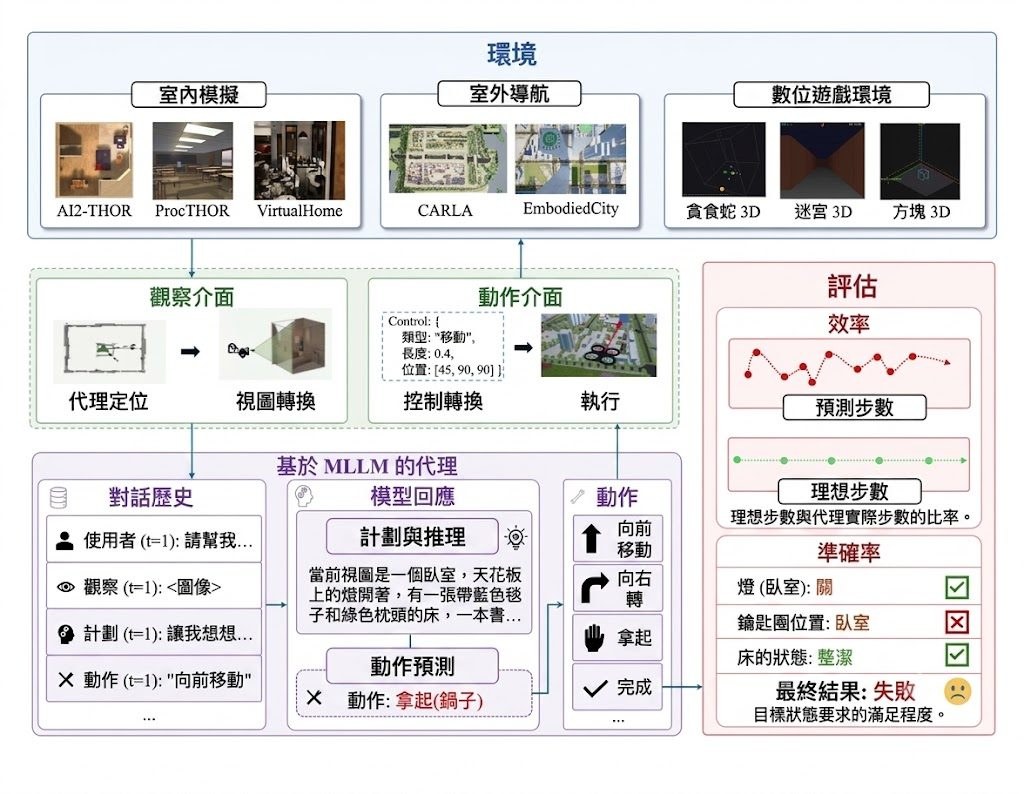
SpatialWorld 是一個用來測試 Multimodal Large Language Models(MLLMs)與代理能力的 benchmark。它把 8 個不同的 3D 模擬後端整合成同一套 observation–action 介面,讓模型只靠自然語言指令、第一身 egocentric RGB 畫面,以及統一的文字動作指令完成任務。
如果你想知道一個模型是否真的懂得在環境中探索、轉向、移動、判斷位置與完成多步驟任務,SpatialWorld 提供了較一致的測試方法。它包含 760 個人工標註任務,覆蓋家居、出行、協作與數碼 3D 遊戲等場景,並以 human-validated terminal-state verifiers 判定結果。
讓代理輸入文字動作,例如 Move、Rotate,再由 action parser 轉成各個模擬器原生指令。這種做法的重點,是避免每個 simulator 各有一套流程,令不同模型之間較容易作橫向比較。
- 統一 8 個 3D backends,減少 simulator-specific pipelines 帶來的比較困難
- 只提供 vision-only partial observability,更接近代理逐步探索的情況
- 除了 task success rate(TSR),亦會看 step efficiency(SE),不只比較有沒有完成
- 已評估 15 個代理,方便對照現有模型表現
從公開結果看,這個項目揭示了目前模型的限制。GPT-5 的平均 TSR 為 17.4%,領先的 open-source 模型 Qwen-3.5 為 14.1%;若看 Physical Overall TSR,GPT-5 只有 14.4%,Qwen-3.5-397B-A17B 為 12.2%。這表示模型即使能理解圖片與文字,也未必能穩定完成需要空間推理與長步驟規劃的任務。
相關模型有 GPT-5、Qwen-3.5、Qwen-3.5-397B-A17B 與 Gemini-3.1-Pro,其中 Gemini-3.1-Pro 在 digital 3D games 達到 39.0% TSR。若你是做 agent、embodied AI、MLLM 評測,或者想比較不同模型在互動式空間任務的差異,SpatialWorld 會是一個很有參考價值的項目。