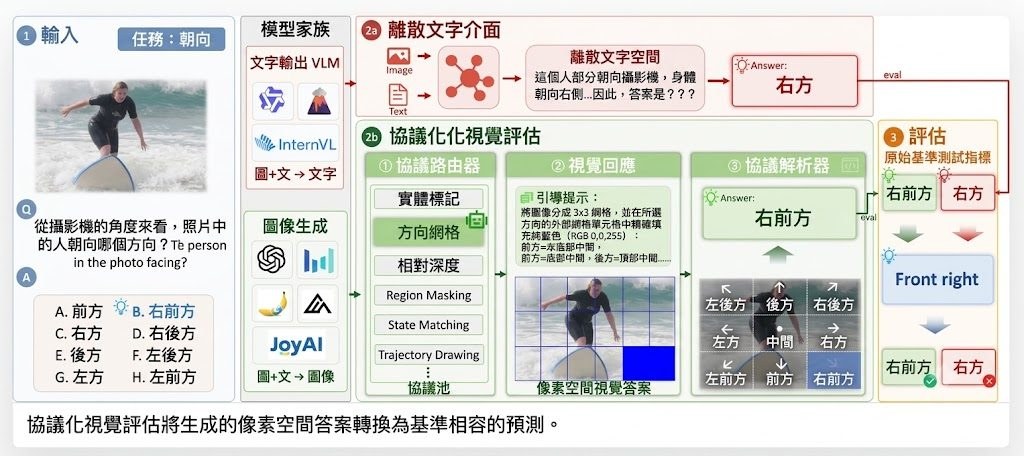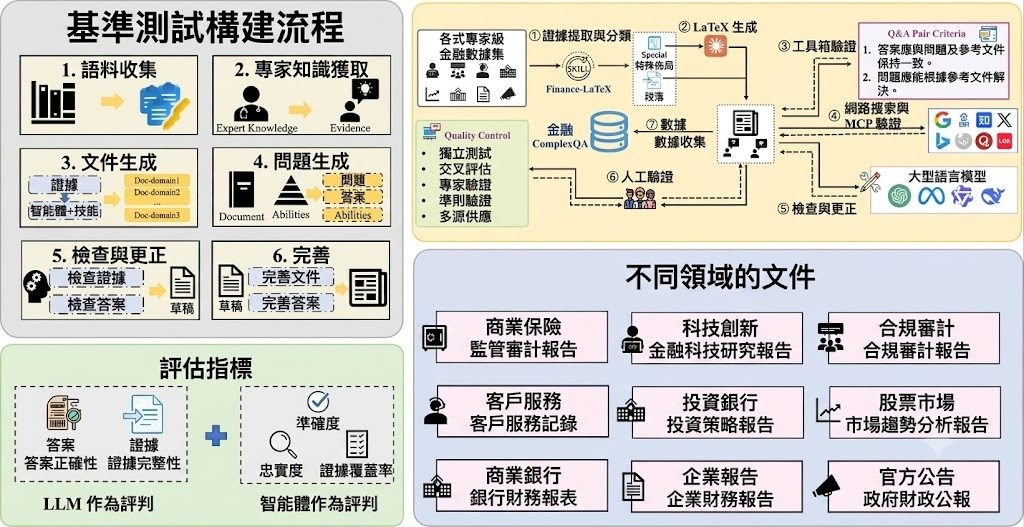
金融問答最容易失真的位置,不是模型識唔識術語,而是它會否真正在整份參考文件入面推理、比對同計數。FinanceComplexQA屬於數據集/Benchmark,焦點不是背答案,而是檢驗 LLMs 和 agents 能否根據完整 reference documents 回答複雜金融問題。
它修正了只靠 parametric knowledge 或抽取單一段落的評測範式。作者把重點放在 document-grounded complex financial QA,要求答案同問題及原始文件一致,並涵蓋 multi-hop reasoning、numerical calculation、comparison、implicit inference、planning、summarization 同 evidence-grounded verification,對 RAG、Agentic workflow 同長文本閱讀能力都有參考價值。
資料結構本身亦有取捨。FinComplexQA-Pro 收錄 2,026 組獨立 QA,按語言、金融場景與任務分類組織;同一題會以 scene_categories 與 task_categories 兩種視角出現,所以總記錄視圖有 4,052 筆。另有 overall 提供 agent_answer、agent_thinking 及 LLM-as-a-judge 分數,但這些分數只適合做診斷訊號,不能當 ground truth。
- 支援中文與英文,但兩個子集覆蓋的文件領域不同,schema 亦不完全一致
- 較適合逐個子目錄讀取 JSONL,而不是一開始合併全部資料
- 可用 exact match、數值容差、F1、semantic similarity 等方法比對輸出
- 附有 Reference_documents,方便追查 PDF 與 LaTeX 原文證據
部署和測試的理解方式相當直接:資料主要在 Hugging Face 發佈,研究團隊可先挑單一語言、單一 task category 載入,再把模型輸出對照 gold answer 或文件證據做評估。它較受惠於做金融 RAG、長文件 QA、Agent 評測或雙語研究的團隊;要留意的是金融事實具時效性,而且項目已明確標示僅供研究與評估,不應延伸成投資、會計、法律或財務建議。