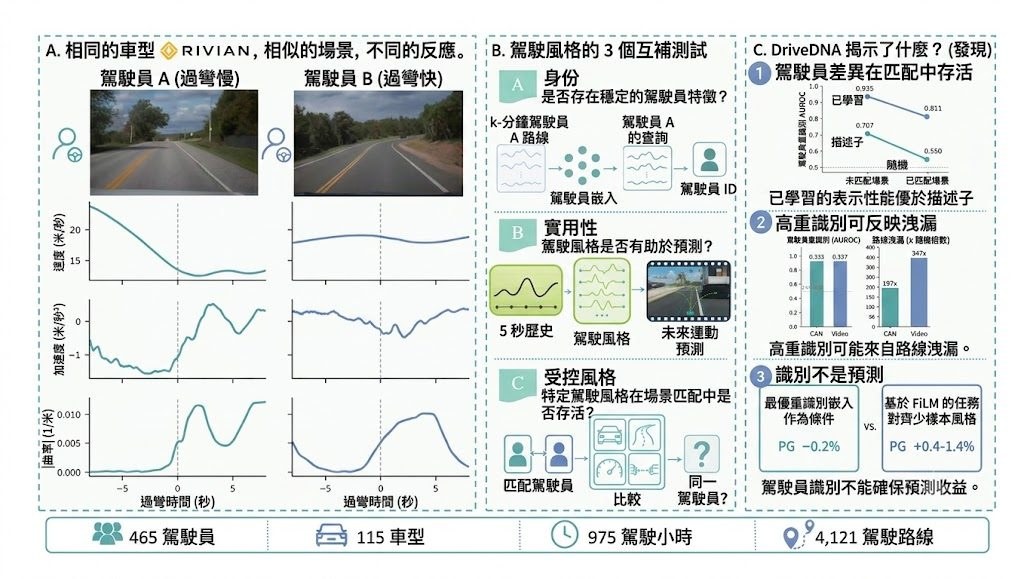
不少駕駛模型聲稱識別「駕駛風格」,但一換車款、路線或交通情境,學到的可能只是車主習慣路段與車輛特性。DriveDNA屬於多模態自然駕駛數據集與 benchmark,核心不是再加一批行車資料,而是把「邊個人在開車」與「開緊咩車、行緊邊條路」分開檢驗,直接處理個人化駕駛建模最常見的捷徑問題。
現有公開資源不是樣本太細、就是把車輛與路線幾乎固定,於是高分未必代表模型捉到穩定的個人風格。作者的做法更像重新定義評測:資料來自 465 位司機、115 款車、4,121 段駕駛,保留 CAN telemetry 與前向道路影片,並移除 automation-engaged frames,只留下 human-controlled driving,再配合 frozen evaluation protocol 與 leakage probes,要求研究者同時報告效用與洩漏風險。
它的價值在於評測不只看 re-identification 準唔準,還加入 personalized behavior prediction,以及在條件匹配下比較風格是否仍然存在。論文亦講得很直白:高 re-ID 可能只是 route leakage,能認出司機,不等於對未來行為預測更有幫助;相比只追單一識別分數,DriveDNA更重視模型有沒有學到可遷移、可解釋的駕駛表徵。
- 規模夠大:465 位司機、975 小時 human-controlled driving、4,121 段駕駛
- 模態完整:10 Hz CAN telemetry 配合同步前向道路影片
- 評測設計針對混淆來源,明確檢查 vehicle、route、condition leakage
- 倉庫已附 code 與 harness,但提供的是 benchmark 與研究流程,不是即插即用產品
私隱與資料治理亦寫得仔細:司機身份用 salted hashes,移除 VIN、裝置識別碼與 GPS,沒有車廂影片與音訊,受控影片版本會模糊人臉與車牌,並禁止 re-identification 與保險、就業、執法評分用途。較適合自動駕駛、駕駛行為建模、VLA 與多模態學習團隊拿來做表徵比較與洩漏檢查;現有資訊可確認倉庫附有 code & harness,但未見完整產品化安裝流程,重點仍是研究 benchmark 與可重現評測。