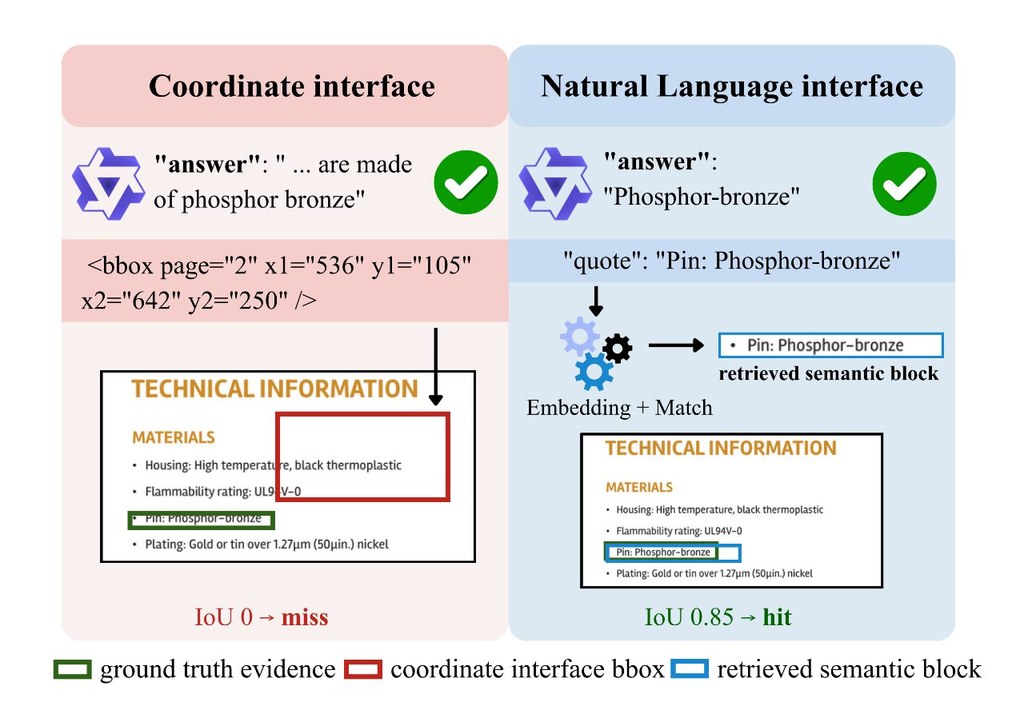
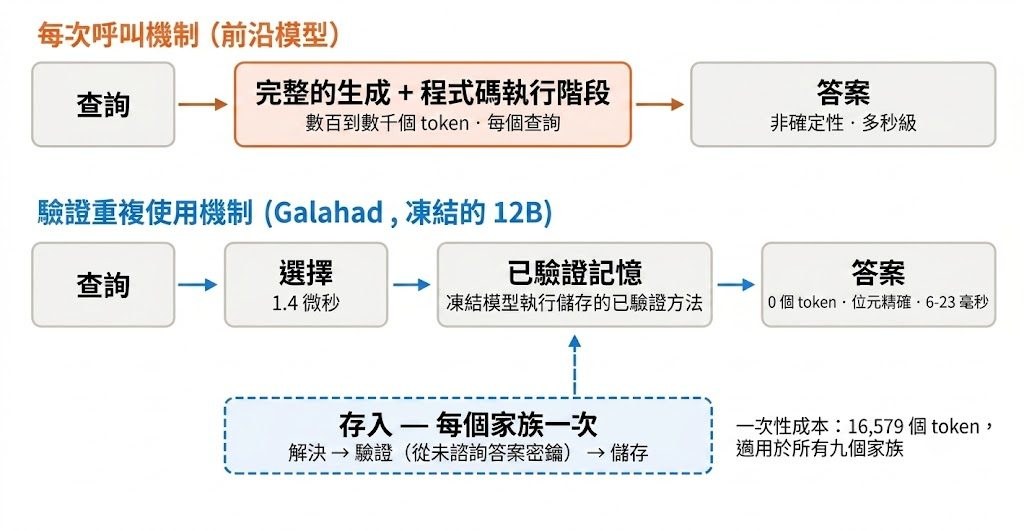
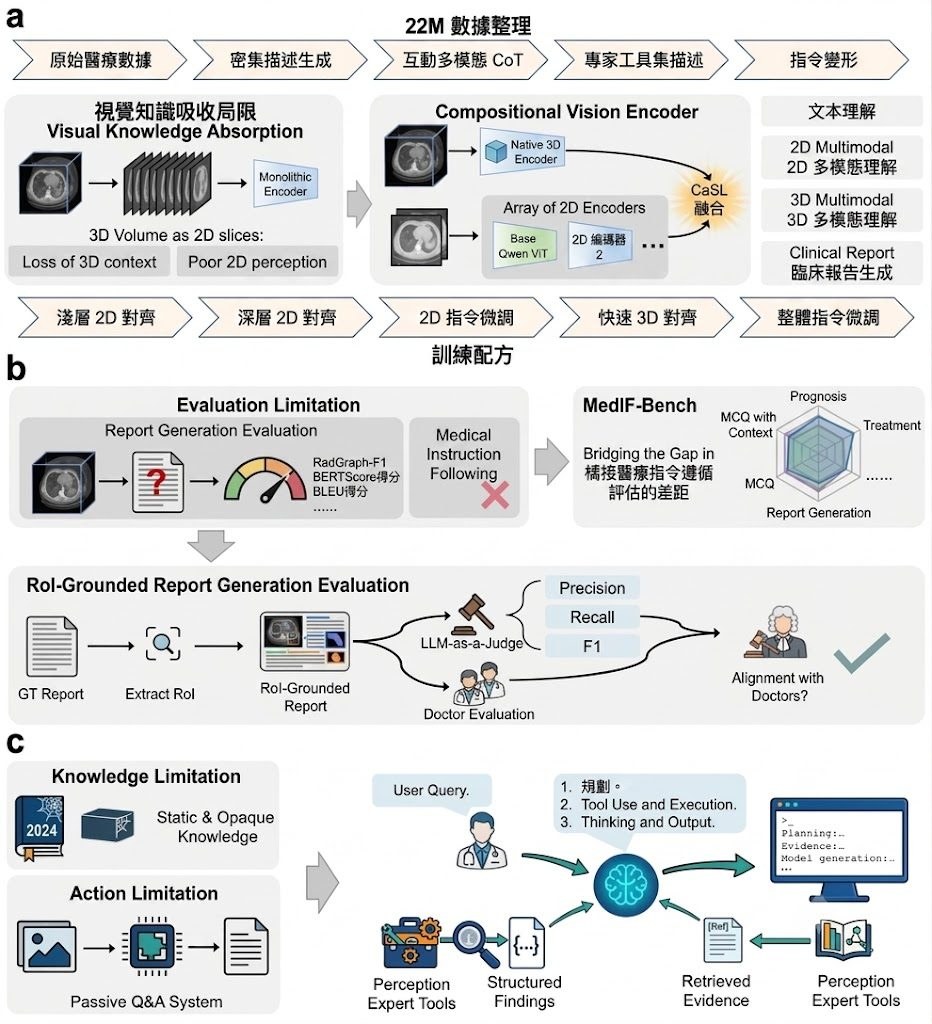
由一張圖片或一段影片出發,Wonder會建立一個可以邊走邊看的互動式 Video World Model,處理的是「鏡頭一直移動,但場景仍要連貫」這個難題。你向前推、左右轉,甚至回到之前看過的位置,畫面都要盡量保持幾何、外觀同動態一致,而唔係每一格重新幻想一次。
呢個項目吸引的地方,在於它兼顧了互動感同穩定性。官方資料指出,Wonder支援 image-to-video 同 video-conditioned generation,提供 6-DoF camera control,並以接近固定延遲維持最長一分鐘的探索;對想做可遊走場景、遊戲世界原型、動畫預覽,或者互動式視覺敘事的人來講,呢種體驗比單次生成短片更有用。
為咗令鏡頭控制唔只停留喺抽象指令,Wonder把相機平移與旋轉轉成可對齊畫面的密集視覺證據,再配合 3D scaffold 同 environment map 去建立可導航空間。它亦保留完整歷史的 KV caches,再用 sparse attention 抽取相關記憶,令系統可以在不明顯拖慢回應下,維持較長距離的一致性。
- 支援 I2V+V2V multimodality,可由圖片或影片開始生成互動世界
- 提供 6-DoF camera control,重點是可探索而唔係只看固定鏡頭片段
- 以 sparse attention 配合完整歷史記憶,改善長時段連貫性
- 官方展示為 16 FPS rollout,頁面上的 32 FPS 影片屬線性插幀後處理
訓練部分用了 Mixture-of-Students 設計,並以 GAN Control Regularization 處理蒸餾時的 camera drift,目標是同時保住控制能力同長期一致性。現階段公開資訊以示範與技術報告為主,Code 同 HuggingFace 尚未釋出;不過單看定位,Wonder已經清楚指向一類更接近「可互動世界」而唔係「一次性影片生成」的世界模型方向。