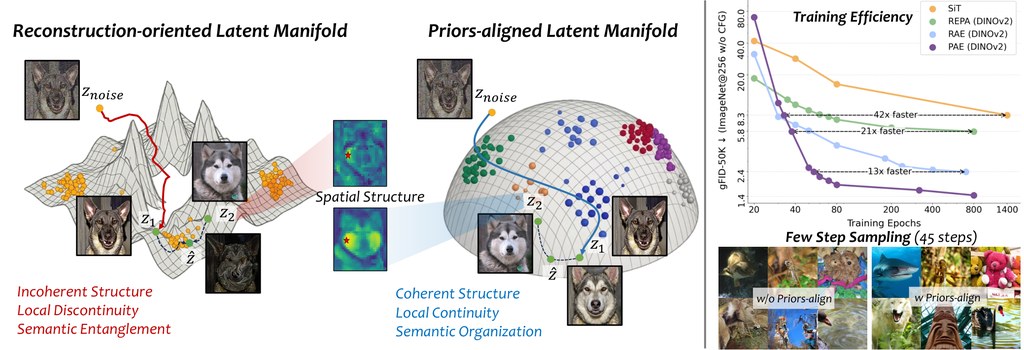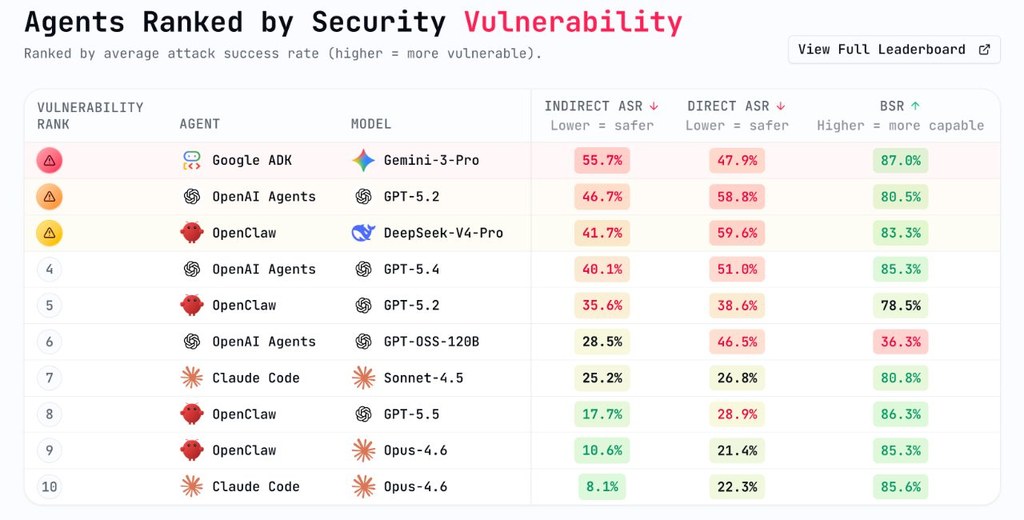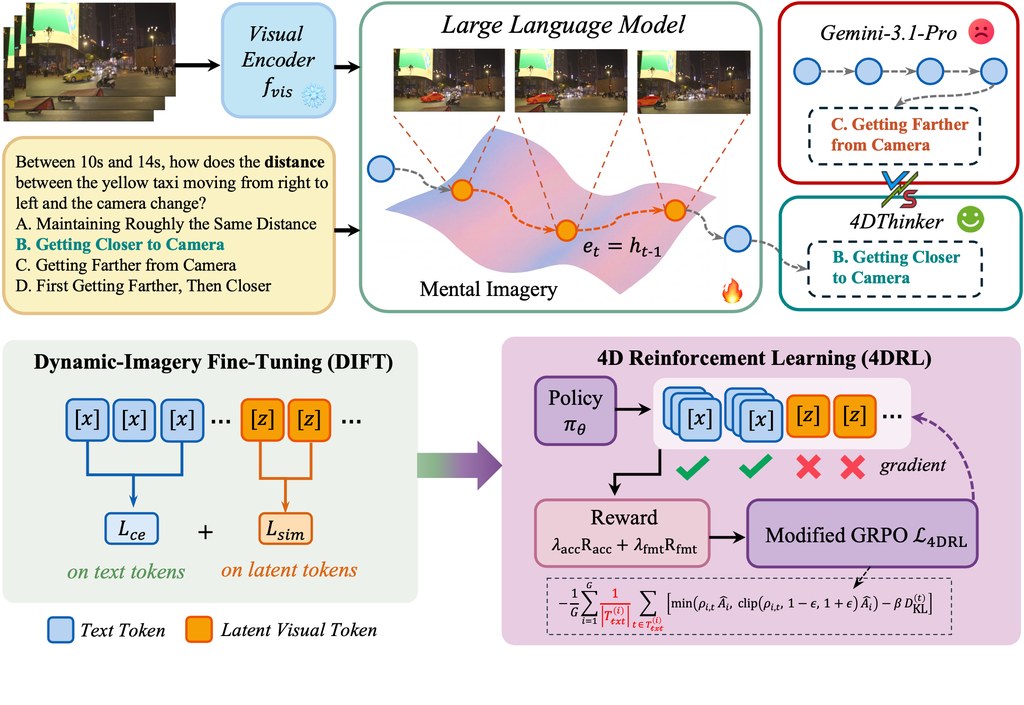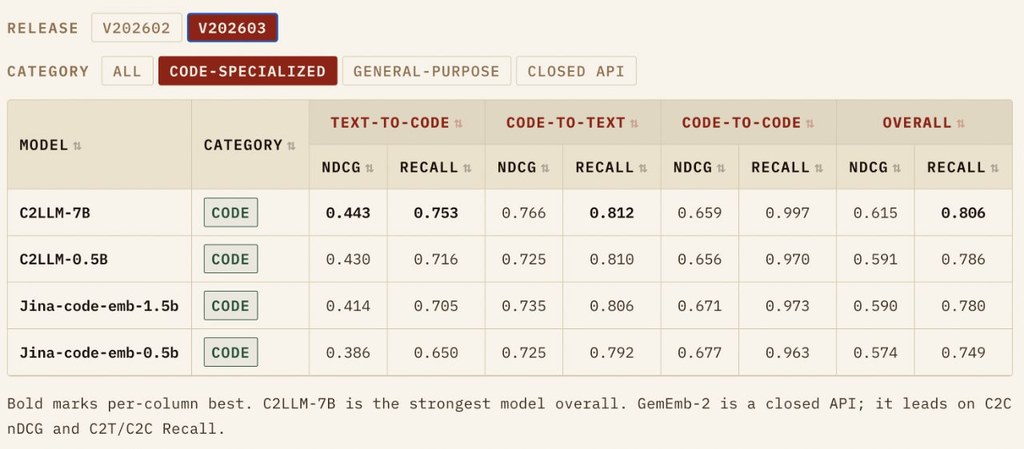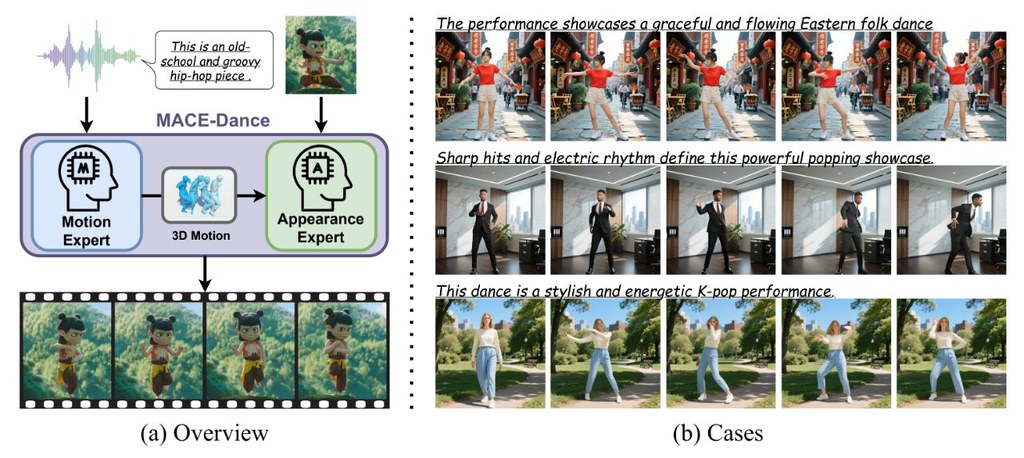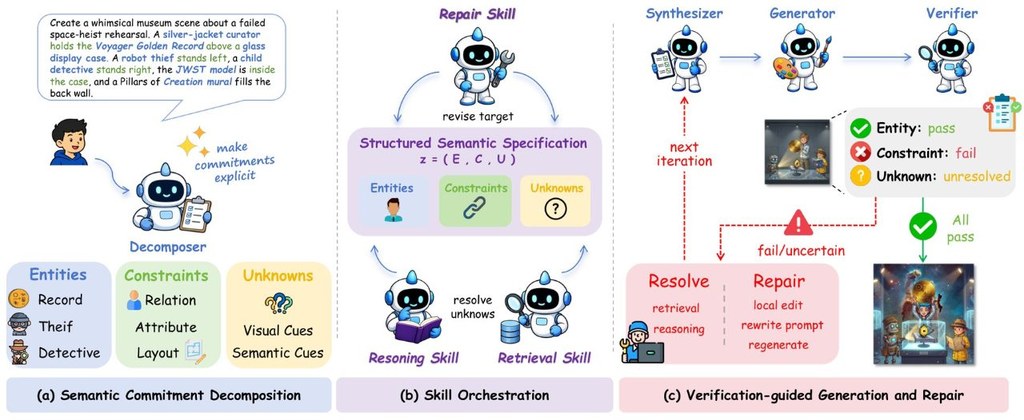
SCOPE 係一個面向複雜圖片生成嘅研究型框架,核心做法唔係單靠一次過輸入長提示詞,而係先將要求拆成可追蹤嘅「語義承諾」,例如人物、物件、關係、限制同未確定資訊。之後每個步驟都圍繞同一份結構化規格運作,減少中途遺漏要求嘅情況。
實際使用上,呢個專案比較似一套流程引擎,而唔係即開即用嘅圖片 App。使用者需要準備 Python 3.10+、設定運行環境,並按需要接駁圖片生成、驗證同搜尋等後端服務;如果想跑完整代理式工作流程,亦需要 Codex CLI。
佢最值得留意嘅創新,在於將「生成失敗咗邊一項」具體化。SCOPE 唔係見結果唔理想就整張圖重來,而係透過驗證同修補階段,集中處理未解決或違反咗嘅承諾,令後續動作更有方向,對多角色、多約束、知識密集型提示尤其重要。
- 以結構化規格保存提示要求,而唔係只靠一段文字
- 將檢索、推理、生成、驗證、修補串成可追蹤流程
- 適合研究同評測複雜圖片生成效果
- 內含配置範例、CLI 工具同 Gen-Arena 評估相關實用程式
如果你係研究人員、工程團隊,或者正測試高要求圖像任務,SCOPE 會比一般單步生成流程更有分析價值。相反,若你只係想快速出圖,呢個專案門檻會較高,因為它重點係流程控制、可驗證性同評估,而唔係簡化操作介面。
整體來講,SCOPE 展示咗一個幾清晰嘅方向:當提示變得愈來愈複雜,單靠模型「自己理解」未必足夠,最好有一套能夠持續記錄、檢查同修正要求嘅機制。以官方資料所見,佢亦配合 Gen-Arena 呢類基準做評估,令成效唔只停留喺示範圖片層面。
Source: https://github.com/nopnor/SCOPE