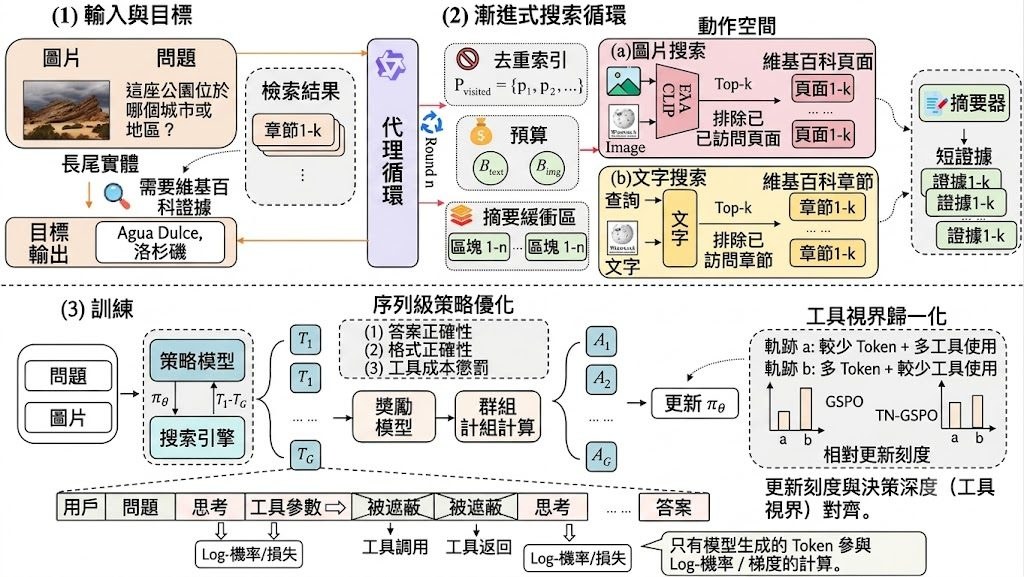
這是一個針對 Knowledge-Based Visual Question Answering(KB-VQA)的研究原型兼訓練項目。它要處理的問題,是模型不只要看懂圖片內容,還要連接外部知識來源例如 Wikipedia,先找對實體,再用足夠證據回答問題。
現有做法多數採用固定的 retrieve-then-generate 流程:先選好 retriever、設好 static top-k,再做一次檢索後直接生成答案。作者認為這種範式遇到 long-tail entities 很脆弱,第一步找錯就難以修正,也不擅長組出 multi-hop 證據鏈;所以 ProMSA 改成 progressive multimodal search agent,讓同一個 MLLM 逐輪決定用 image search、text search,還是 stop。
這個項目的取向很明確:它不是單純把檢索接到模型前面,而是把搜尋本身變成推理流程一部分。配合 de-duplication exclusion list、tool-call budget 同 reward penalty,它會避免重覆撈同一批內容,亦會在證據足夠時停手,減少無效工具呼叫;訓練上再用 TN-GSPO,而不是只靠 GRPO 或 vanilla GSPO,目標是令長度與工具步數不同的軌跡都能較穩定更新。
- 支援 image search、text search、stop 三種動作
- 針對錯誤首次檢索加入 failure recovery 與 multi-hop 搜尋
- 採用 veRL 工具介面,包含 multi-turn rollout、reward 與 loss
- policy backbone 包括 Qwen/Qwen2.5-VL-7B-Instruct、Qwen/Qwen3-VL-2B-Instruct、Qwen/Qwen3-VL-8B-Instruct
網頁 已交代 Installation、Data & Model Preparation、Service Architecture、Training 同 Evaluation,表示它不只是概念展示,而是有完整實驗流程的研究項目;不過部署時應預期需要 Python 3.10+、veRL、外部搜尋服務同相應資料準備。結果描述提到在 E-VQA 與 InfoSeek 對強 RAG 和 agent baselines 有一致提升,但目前提供的是研究報告式結論,較適合做 KB-VQA、multimodal agent、RAG policy 訓練的團隊參考,而不是即裝即用的通用產品。