MultiHashFormer 是一個生成式語言模型研究項目,同時提供 Qwen3 相關實作、訓練腳本與詞彙擴充流程。它要解決的是傳統 embedding matrix 會隨 vocabulary size 線性膨脹,令模型難以用固定參數量吸收更多詞彙、語種或新領域內容。
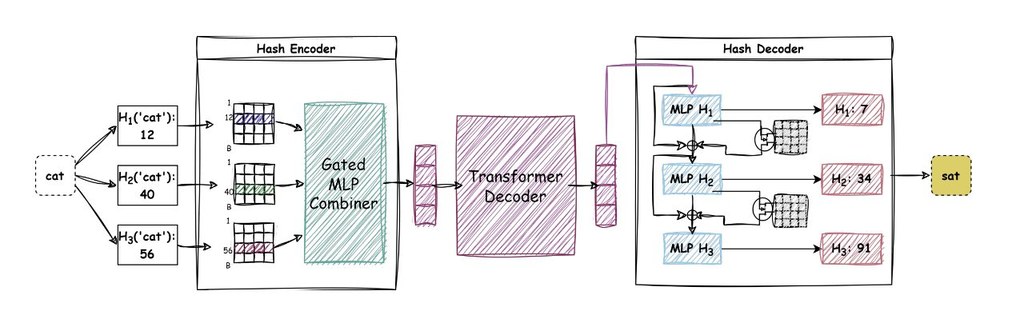
現有 hash-based 做法多數採用 many-to-one mappings,把多個 token 壓到同一個 hash index,這在 encoder-only 模型尚可運作,但放到 causal LMs 就會出現解碼歧義:模型預測到共享 index,未必能準確還原原來那個 token。MultiHashFormer 的做法是為每個 token 建立 unique hash signature,用多個獨立 hash functions 產生一串離散 hash IDs,再交由 Hash Encoder 壓成 latent vector,最後由 Hash Decoder 生成下一個 token 的 hash signature。
這個設計的取向很明確:它不是單純縮小 embedding,而是重組「token 如何表示、如何生成」這條路徑,目標是在保持參數 footprint 固定的前提下,仍可做 autoregression。來源資料亦顯示作者把它放到 100M、1B、3B 規模,並提供 standard 與 MHF 兩組訓練腳本,方便直接對照 baseline,不過 README 未完整列出所有 benchmark 數字,閱讀時應以論文結果為準。
部署理解上,這個項目比較接近研究代碼而非即裝即用產品:preprocessing 內有英文預訓練資料處理腳本,training 內分 standard 與 MHF 訓練流程,vocab_expansion 則涵蓋 tokenizer 訓練、資料準備、continual pretraining 與 expanded_tokenizer。依賴包括 transformers、flash_attn、tokenizers、lm_eval 與 mmh3,代表它面向的是已有 Python 深度學習環境、想重現論文或測試詞彙擴充的人。
- 項目類型:研究原型兼模型訓練代碼,核心是 hash-based autoregressive language modeling。
- 主要差異:不再用 many-to-one hashing 直接代表 token,而是生成可還原的 unique hash signature。
- 適合情境:比較標準 Transformer 與 MHF、研究 vocabulary expansion、測試固定參數量下的多語詞表延展。
- 相關模型:Qwen3 標準版、qwen3_ori、qwen3_hashformer,以及 100M/1B/3B 多個 HuggingFace checkpoints。
整體來看,這個項目的價值在於它不只提出一個更省參數的表示法,還試圖修補 hash 方法長期無法自然用於生成式模型的缺口。對研究語言模型架構、詞表擴展與參數效率的團隊來說,它比一般「換個 tokenizer」更值得細看,因為連輸入表示與下一 token 生成機制都一併改寫了。