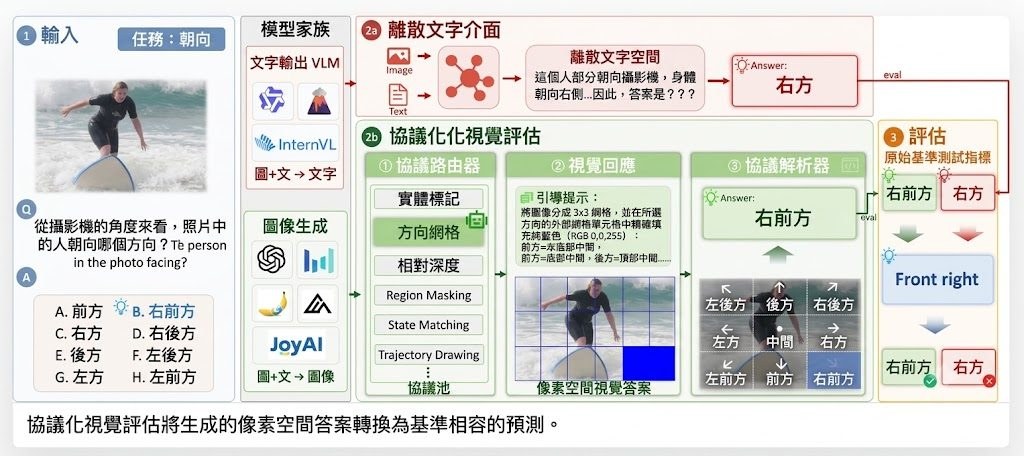
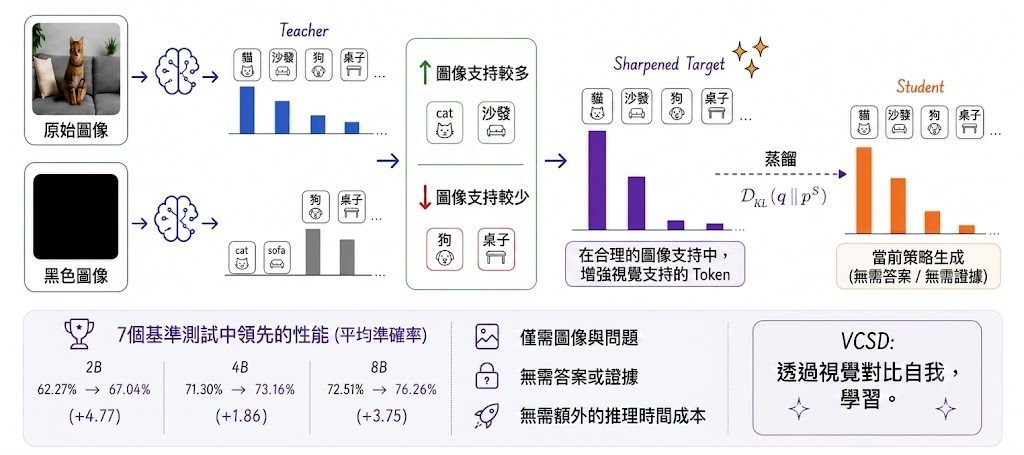
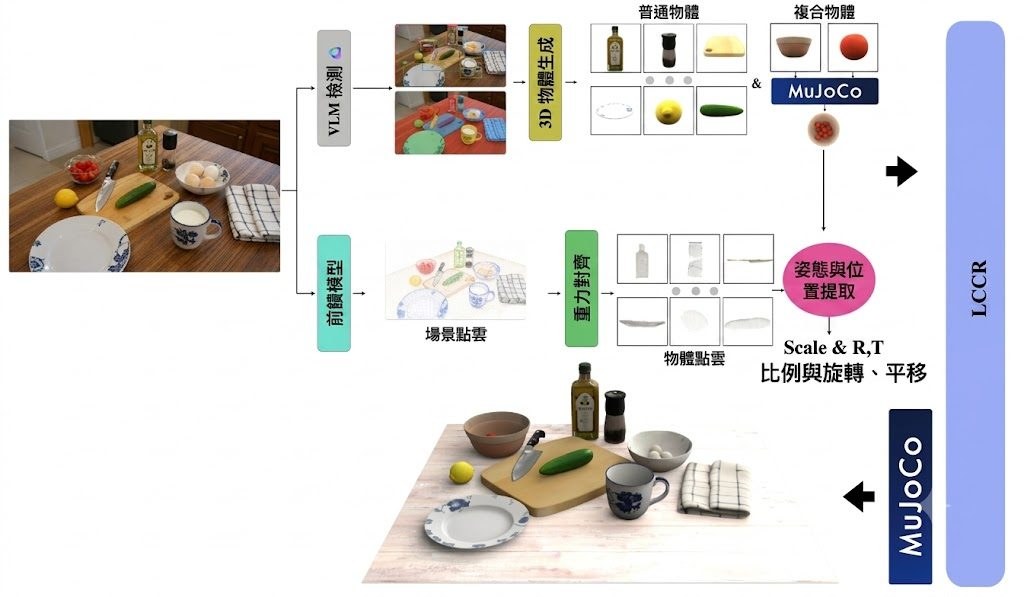
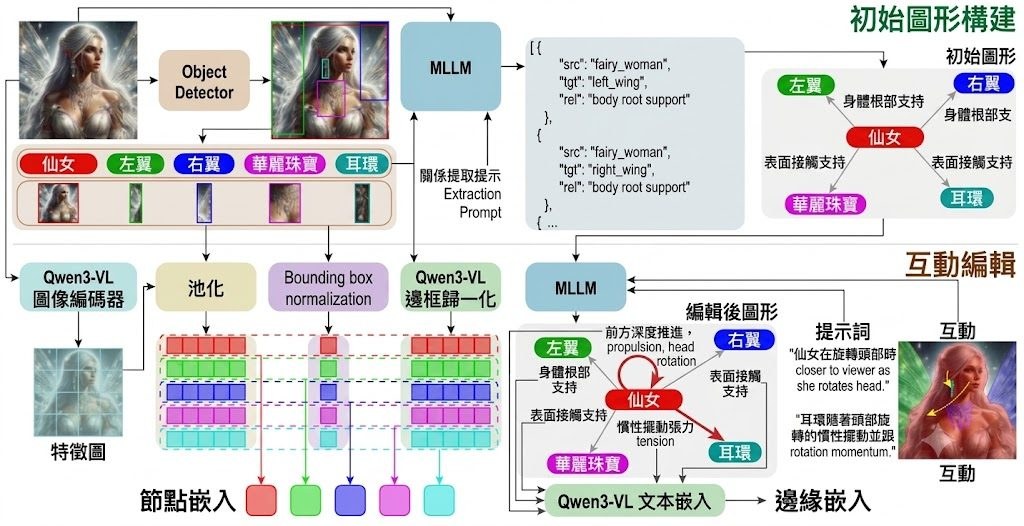
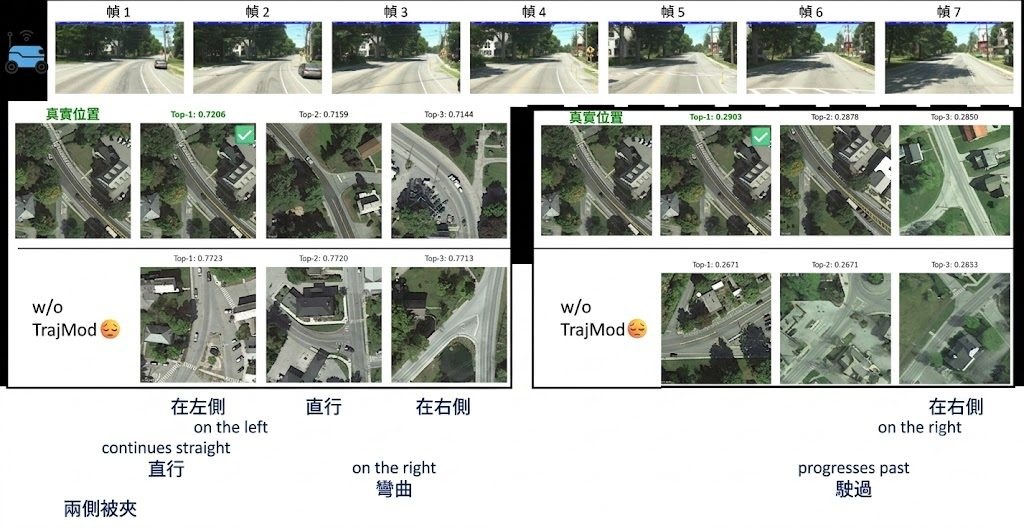
改圖最怕模型聽得明文字,卻改壞原本場景結構;生圖亦常見字排得唔準、物件關係走位。JoyAI-Image就係朝住呢個痛點落手,定位屬於多模態基礎模型,把影像理解、text-to-image 生成同指令式編輯放入同一個模型家族,重點處理空間理解不足帶來的失真與失控。
唔係把理解模型同生成模型鬆散拼埋,而係用 8B Multimodal Large Language Model (MLLM) 配 16B Multimodal Diffusion Transformer (MMDiT),強調理解、生成、編輯之間的閉環協作。換句話說,模型唔只讀圖後再畫圖,仲會利用視角變換等生成結果反過來補強空間推理,呢點令它在 grounded generation、關係定位同可控編輯上有更鮮明方向。
現有公開內容顯示,部署路線算完整,已提供 Hugging Face 權重、Diffusers 版本、ComfyUI 原生支援,同埋可直接參考的 workflow;另外亦有 Spatial Edit 同 General Edit 示範空間。對內容製作、電商視覺、設計流程或者研究多模態編輯的人,較值得留意的是它不只處理單次修圖,仲想處理長文字排版、版面忠實度、多視角生成,以及「指定物件移去指定位置」呢類容易出錯的操作。
JoyAI Image Edit Plus in ComfyUI - How Does it Compare?

- 把理解、生成、編輯整合到同一條多模態流程
- 核心賣點係較強的 spatial intelligence,而不只是畫面更靚
- 已有 Diffusers 與 ComfyUI 兩條使用路線,測試門檻較研究原型低
- 延伸到 OpenSpatial data engine 同 OpenSpatial-3M dataset,反映它連資料與訓練配方都一併公開
效能方面,儲存庫描述集中在能力展示與訓練設計,現階段較適合把它理解成一個方向清晰、工具鏈逐步成熟的開源影像模型項目。最吸引之處唔係單一指標,而係它把空間理解當成生成與編輯的核心能力,對需要更穩定版面、關係同位置控制的工作流,確實比單講畫質更實用。