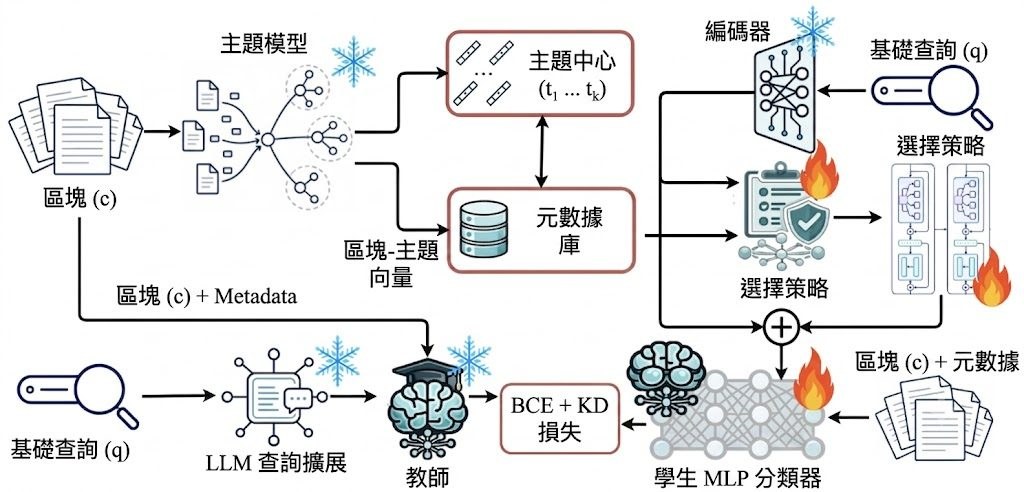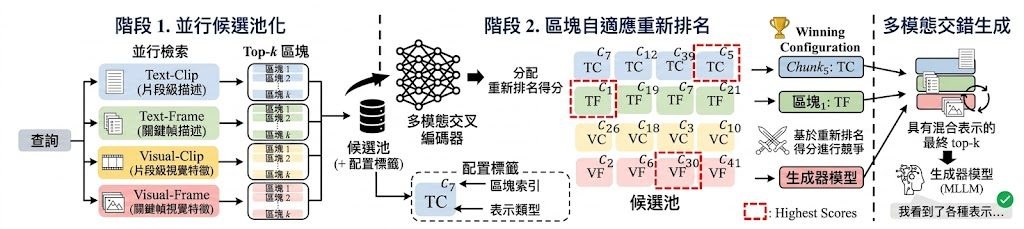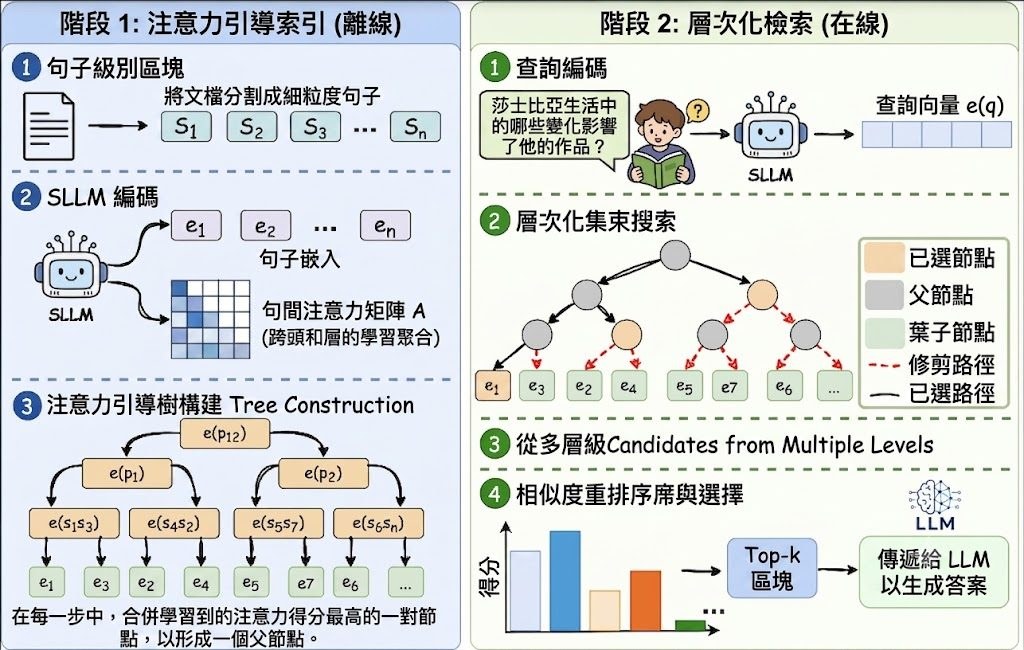
現時不少 RAG(Retrieval-Augmented Generation)做法,通常在「細粒度 chunk 準確但零碎」與「大段內容連貫但嘈雜」之間取捨;有些方法靠 LLM-guided chunking、single-level context expansion,或 hierarchical summarization 去補救,但代價是要額外 LLM 呼叫、只支援單一層級擴展,或者在摘要過程流失資訊。SproutRAG 提出的方向,是用 attention-guided hierarchical RAG framework,把句子逐步組成語意連貫的多層結構,再做 multi-granularity retrieval。
這是一個 RAG 工具/框架,重點不是單獨一個模型,而是把索引、檢索、reranking、答案生成與評測串成完整流程,處理長文件問答中「證據要夠準又要保留上下文」的問題。它用 YAML 或 JSON config 驅動 CLI,每一步各有設定,輸出統一是 JSON,對接下游工具和保留可重現紀錄都幾方便。
部署和測試思路算清楚:先準備 JSONL 文件,之後分開建立 index、執行 retrieve、再 answer;若要研究效果,還可 train 和 evaluate。附加套件分別對應 PyYAML、ROUGE-L、METEOR、BERTScore 及 spaCy,反映這個項目除了生成,也很著重檢索與答案品質的量化比較。
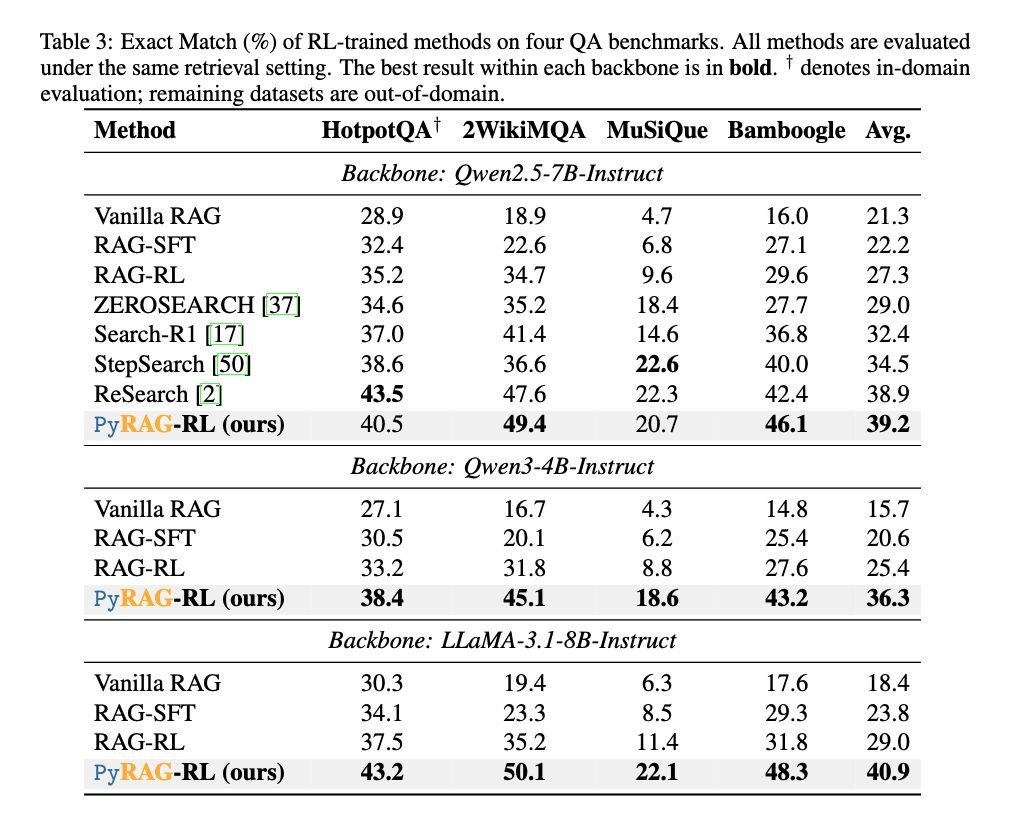
和常見 flat retrieval 相比,SproutRAG 較值得留意的是 hierarchical attention-based indexing 加上 hierarchical beam search:它不是只撈單一粒度片段,而是沿樹狀結構找不同大小的候選證據。論文資料指出,它在四個 benchmark 的 information efficiency(IE)平均比最強 baseline 高 6.1%,但目前公開說明未見太多資源消耗與大型部署細節,訓練部分亦提到 MS MARCO 只先載入 v2.1 train split 的首 30k 筆樣本,代表現階段較適合研究、評測與流程驗證。
- 適合需要處理長文件的 RAG 項目,例如法律、科研、知識庫問答
- 配置檔主導流程,方便版本控制、重現實驗與比較不同設定
- 支援 optional reranking 與生成評測,不只是單做檢索
- 相關模型包括 sentence-transformers/all-MiniLM-L6-v2,底層依賴 PyTorch 2.x 與 Transformers 4.51+
- 若你想比較多粒度證據檢索與傳統 chunk-based RAG 的差異,這個項目很有研究價值