這項研究由 KAIST 與 Qualcomm AI Research、Qualcomm Korea 團隊合作提出,聚焦長時間第一身影片中的 Retrieval-augmented generation(RAG)。作者指出,現有 VideoRAG 常沿用「每條查詢只配一種 modality 與一種 temporal granularity」的固定範式,但長影片的證據片段差異很大,單一設定未必適合全部片段;加上不少既有 benchmark 的問題甚至不用看影片也能答中,令最終分數難以反映檢索是否真的做對。
因此,團隊提出 V-RAGBench,把資料整理成 ⟨query, evidence chunk, answer⟩ triplets,明確分開查詢、證據片段與答案。這種設計針對的是過去「只看最終回答正確率」的盲點,讓研究者可以更忠實地分開檢查 retrieval 與 generation,知道系統究竟是靠對的影片片段,還是靠語言偏見、常識或靜態線索作答。
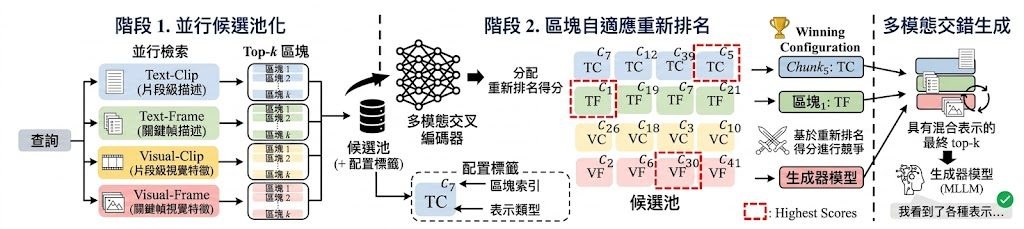
方法上,作者再提出 CARVE。它不是替整條查詢預先選定一種設定,而是讓多個 retriever 以不同 modality 與 granularity 並行工作,再用 chunk-adaptive reranking 為每個 evidence chunk 挑出最合適的 winning configuration。之後,這些片段會連同各自勝出的設定一併送入 generator,形成 interleaved evidence,令檢索階段的片段級決策延續到生成階段。
對想使用這個項目的人來說,切入點很清楚:先用 V-RAGBench 測試自己的 VideoRAG 流程,分開看檢索與生成表現;若系統目前仍採用查詢級單一設定,可再比較 CARVE 這種片段級配置方式。這種思路較適合長影片問答、egocentric video 分析,以及需要從多模態證據中找出正確時間片段的 Agentic 系統。
- V-RAGBench 以 evidence chunk 為核心,補足舊 benchmark 無法準確檢查檢索對錯的問題
- CARVE 改為片段級選擇 configuration,不再假設一條查詢只需一套 modality/granularity
- 作者指出 generator 最後接收的 chunks 會交錯來自多種 configuration,這是 query-level 方法做不到的
- 論文稱 CARVE 勝過 8 個近期 VideoRAG baselines,顯示片段級決策在長影片檢索更有優勢
整體來看,這項工作不是單純再加一個 VideoRAG 方法,而是先批評舊有評測與建模範式,再用新 benchmark 和新 retrieval framing 一起修正問題。如果你關心的是長影片 RAG 到底應該取回什麼、以及取回後怎樣交給模型使用,這項研究提供了相當清晰的分析框架。