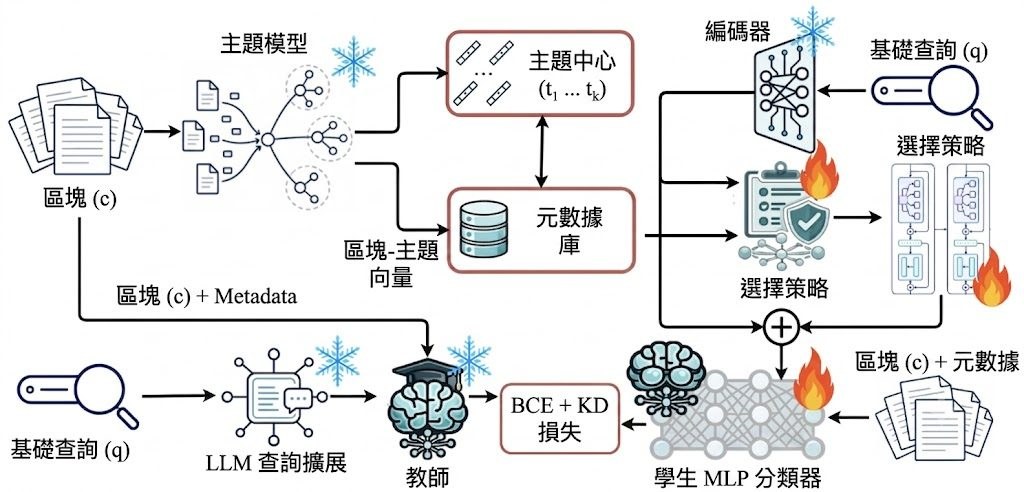
現時不少 RAG 會用 dense retrieval,直接把查詢同文本 chunk 的 embedding 拿去比對;當 chunk 切得較粗、語料又雜,語意接近未必等於真正答到問題。MCompassRAG 屬於檢索框架,做法是替段落加入 topic metadata,再用 LLM teacher 離線產生判斷訊號,蒸餾成一個輕量 retriever,修正「只靠 chunk embedding 排名」這種固定範式的偏差。
它的取向幾清楚:把較重的判斷放在訓練前期,推理階段只保留 metadata bank、embedding lookup 同小型 scorer,所以標明可做到 zero LLM calls at inference。這個取捨很適合想保留檢索速度,但又嫌傳統向量檢索太粗糙的團隊;代價是前處理較長,要先訓練 topic model,再生成 distillation data。
項目流程分成幾步:先準備語料、訓練 topic model、生成蒸餾資料、建立 metadata index,再訓練 retriever。環境上要 Python 3.10+、PyTorch 2.x、Transformers 4.51+,而且建議有 CUDA GPU;OpenRouter API key 只在 Step 2 — Generate distillation data 需要,之後檢索本身不依賴 LLM 連線。
可留意的重點有幾個:
– 不只重排結果,而是把 topic signal 放進 retriever embedding space 一齊學習
– 支援可插拔 topic model backend,現成有 CEMTM、ETM、CWTM、SoftLTM
– 推理成本貼近 embedding model latency,較適合高頻查詢場景
– 比起純 dense retrieval,更著重 paragraph-level evidence quality
作者強調它會在 complex retrieval benchmarks 提升 evidence quality 同效率,但目前倉庫內容較像 research implementation,未見非常完整的產品化基準表。較受惠的會是做知識庫問答、文件搜尋、企業內部檢索的團隊,尤其當資料主題分散、段落切分又未必夠細時,MCompassRAG 的 topic compass 概念比單純換一個 embedding model 更有分析價值。
GitHub: https://github.com/AmirAbaskohi/MCompassRAG